In this post we'll build a database in 400 lines of code with basic support for five standard SQL transaction levels: Read Uncommitted, Read Committed, Repeatable Read, Snapshot Isolation and Serializable. We'll use multi-version concurrency control (MVCC) and optimistic concurrency control (OCC) to accomplish this. The goal isn't to be perfect but to explain the basics in a minimal way.
You don't need to know what these terms mean in advance. I did not understand them before doing this project. But if you've ever dealt with SQL databases, transaction isolation levels are likely one of the dark corners you either 1) weren't aware of or 2) wanted not to think about. At least, this is how I felt.
While there are many blog posts that list out isolation levels, I haven't been able to internalize their lessons. So I built this little database to demonstrate the common isolation levels for myself. It turned out to be simpler than I expected, and made the isolation levels much easier to reason about.
Thank you to Justin Jaffray, Alex Miller, Sujay Jayakar, Peter Veentjer, and Michael Gasch for providing feedback and suggestions.
All code is available on GitHub.
Why do we need transaction isolation?
If you already know the answer, feel free to skip this section.
When I first started working with databases in CRUD applications, I did not understand the point of transactions. I was fairly certain that transactions are locks. I was wrong about that, but more on that later.
I can't remember exact code I wrote, but here's something I could have written:
with database.transaction() as t:
users = t.query("SELECT * FROM users WHERE group = 'admin';")
ids = []
for user in users:
if some_complex_logic(user):
ids.append(user.id)
t.query("UPDATE users SET metadata = 'some value' WHERE id IN ($1);", ids)
I would have thought that all users that were seen from the initial
SELECT who matched the some_complex_logic filter would be exactly
the same that are updated in my second SQL statement.
And if I were using SQLite, my guess would have been correct. But if I were using MySQL or Postgres or Oracle or SQL Server, and hadn't made any changes to defaults, that wouldn't necessarily be true! We'll discover exactly why throughout this post.
For example, some other connection and transaction could have set a
user's group to admin after the initial SELECT was
executed. It would then be missed from the some_complex_logic check
and from the subsequent UPDATE.
Or, again after our initial SELECT, some other connection could have
modified the group for some user that previously was admin. It
would then be incorrectly part of the second UPDATE statement.
These are just a few examples of what could go wrong.
This is the realm of transaction isolation. How do multiple transactions running at the same time, interacting with the same data, interact with each other?
The answer is: it depends. The SQL standard itself loosely prescribes four isolation levels. But every database implements these four levels slightly differently. Sometimes using entirely different algorithms. And even among the standard levels, the default isolation level for each database differs.
Funky bugs that can show up across databases and across isolation levels, often dependent on particular details of common ways of implementing isolation levels, create what are called "anomalies". Examples include intimidating terms like "dirty reads" and "write cycles" and G2-Item.
The topic is so complex that we've got decades of research papers critiquing SQL isolation levels, categorization of common isolation anomalies, walkthroughs of anomalies by Martin Kleppmann in Designing Data-Intensive Applications, Martin Kleppman's Hermitage project documenting common anomalies across isolation levels in major databases, and the ACIDRain paper showing isolation-related bugs in major open-source ecommerce projects.
These aren't just random links. They're each quite interesting. And particularly for practitioners who don't know why they should care, check out Designing Data-Intensive Applications and the last link on ACIDRain.
And this is only a small list of some of the most interesting research and writing on the topic.
So there's a wide variety of things to consider:
- Not every database implements transaction isolation levels identically, resulting in different behavior
- Not all researchers agree, and not all database developers agree, on what any given isolation level means
- Not every database has the same default isolation level, and most developers tend not to change the default
- Not every developer is correctly using the isolation level they pick (default or not)
Transaction isolation levels are basically vibes. The only truth for real projects is Martin Kleppmann's Hermitage project that catalogs behavior across databases. And a truth some people align with is Generalized Isolation Level Definitions.
So while all these linked works above are authoritative, and even though we can see that there might be some anomalies we have to worry about, the research can still be difficult to internalize. And many developers, my recent self included, do not have a great understanding of isolation levels.
Throughout this post we'll stick to informal definitions of isolation levels to keep things simple.
Let's dig in.
Locks? MVCC?
Historically, databases implemented isolation with locking algorithms such as Two-Phase Locking (not the same thing as Two-Phase Commit). Multi-version concurrency control (MVCC) is an approach that lets us completely avoid locks.
It's worthwhile to note that while we will validly not use locks (implementing what is called optimistic concurrency control or OCC), most MVCC databases do still use locks for certain things (implementing what is called pessimistic concurrency control).
But this is the story of databases in general. There are numerous ways to implement things.
We will take the simpler lockless route.
Consider a key-value database. With MVCC, rather than storing only the value for a key, we would store versions of the value. The version includes the transaction id (a monotonic incrementing integer) wherein the version was created, and the transaction id wherein the version was deleted.
With MVCC, it is possible to express transaction isolation levels almost solely as a set of different visibility rules for a version of a value; rules that vary by isolation level.
So we will build up a general framework first and discuss and implement each isolation level last.
Scaffolding
We'll build an in-memory key-value system that acts on transactions. I usually try to stick with only the standard library for projects like this but I really wanted a sorted data structure and Go doesn't implement one.
In main.go, let's set up basic helpers for assertions and debugging:
package main
import (
"fmt"
"os"
"slices"
"github.com/tidwall/btree"
)
func assert(b bool, msg string) {
if !b {
panic(msg)
}
}
func assertEq[C comparable](a C, b C, prefix string) {
if a != b {
panic(fmt.Sprintf("%s '%v' != '%v'", prefix, a, b))
}
}
var DEBUG = slices.Contains(os.Args, "--debug")
func debug(a ...any) {
if !DEBUG {
return
}
args := append([]any{"[DEBUG]"}, a...)
fmt.Println(args...)
}
As mentioned previously, a value in the database will be defined with start and end transaction ids.
type Value struct {
txStartId uint64
txEndId uint64
value string
}
Every transaction will be in an in-progress, aborted, or committed state.
type TransactionState uint8
const (
InProgressTransaction TransactionState = iota
AbortedTransaction
CommittedTransaction
)
And we'll support a few major isolation levels.
// Loosest isolation at the top, strictest isolation at the bottom.
type IsolationLevel uint8
const (
ReadUncommittedIsolation IsolationLevel = iota
ReadCommittedIsolation
RepeatableReadIsolation
SnapshotIsolation
SerializableIsolation
)
We'll get into detail about the meaning of the levels later.
A transaction has an isolation level, an id (monotonic increasing integer), and a current state. And although we won't make use of this data yet, transactions at stricter isolation levels will need some extra info. Specifically, stricter isolation levels need to know about other transactions that were in-progress when this one started. And stricter isolation levels need to know about all keys read and written by a transaction.
type Transaction struct {
isolation IsolationLevel
id uint64
state TransactionState
// Used only by Repeatable Read and stricter.
inprogress btree.Set[uint64]
// Used only by Snapshot Isolation and stricter.
writeset btree.Set[string]
readset btree.Set[string]
}
We'll discuss why later.
Finally, the database itself will have a default isolation level that each transaction will inherit (for our own convenience in tests).
The database will have a mapping of keys to an array of value versions. Later elements in the array will represent newer versions of a value.
The database will also store the next free transaction id it will use to assign ids to new transactions.
type Database struct {
defaultIsolation IsolationLevel
store map[string][]Value
transactions btree.Map[uint64, Transaction]
nextTransactionId uint64
}
func newDatabase() Database {
return Database{
defaultIsolation: ReadCommittedIsolation,
store: map[string][]Value{},
// The `0` transaction id will be used to mean that
// the id was not set. So all valid transaction ids
// must start at 1.
nextTransactionId: 1,
}
}
To be thread-safe: store, transactions,
and nextTransactionId should be guarded by a mutex. But
to keep the code small, this post will not use goroutines and thus
does not need mutexes.
There's a bit of book-keeping when creating a transaction, so we'll make a dedicated method for this. We must give the new transaction an id, store all in-progress transactions, and add it to database transaction history.
func (d *Database) inprogress() btree.Set[uint64] {
var ids btree.Set[uint64]
iter := d.transactions.Iter()
for ok := iter.First(); ok; ok = iter.Next() {
if iter.Value().state == InProgressTransaction {
ids.Insert(iter.Key())
}
}
return ids
}
func (d *Database) newTransaction() *Transaction {
t := Transaction{}
t.isolation = d.defaultIsolation
t.state = InProgressTransaction
// Assign and increment transaction id.
t.id = d.nextTransactionId
d.nextTransactionId++
// Store all inprogress transaction ids.
t.inprogress = d.inprogress()
// Add this transaction to history.
d.transactions.Set(t.id, t)
debug("starting transaction", t.id)
return &t
}
And we'll add a few more helpers for completing a transaction, for fetching a transaction by id, and for validating a transaction.
func (d *Database) completeTransaction(t *Transaction, state TransactionState) error {
debug("completing transaction ", t.id)
// Update transactions.
t.state = state
d.transactions.Set(t.id, *t)
return nil
}
func (d *Database) transactionState(txId uint64) Transaction {
t, ok := d.transactions.Get(txId)
assert(ok, "valid transaction")
return t
}
func (d *Database) assertValidTransaction(t *Transaction) {
assert(t.id > 0, "valid id")
assert(d.transactionState(t.id).state == InProgressTransaction, "in progress")
}
The final bit of scaffolding we'll set up is an abstraction for database connections. A connection will have at most associated one transaction. Users must ask the database for a new connection. Then within the connection they can manage a transaction.
type Connection struct {
tx *Transaction
db *Database
}
func (c *Connection) execCommand(command string, args []string) (string, error) {
debug(command, args)
// TODO
return "", fmt.Errorf("unimplemented")
}
func (c *Connection) mustExecCommand(cmd string, args []string) string {
res, err := c.execCommand(cmd, args)
assertEq(err, nil, "unexpected error")
return res
}
func (d *Database) newConnection() *Connection {
return &Connection{
db: d,
tx: nil,
}
}
func main() {
panic("unimplemented")
}
And that's it for scaffolding. Now set up the go module and make sure this builds.
$ go mod init gomvcc
go: creating new go.mod: module gomvcc
go: to add module requirements and sums:
go mod tidy
$ go mod tidy
go: finding module for package github.com/tidwall/btree
go: found github.com/tidwall/btree in github.com/tidwall/btree v1.7.0
$ go build
$ ./gomvcc
panic: unimplemented
goroutine 1 [running]:
main.main()
/Users/phil/tmp/main.go:166 +0x2c
Great!
Transaction management
When the user asks to begin a transaction, we ask the database for a new transaction and assign it to the current connection.
func (c *Connection) execCommand(command string, args []string) (string, error) {
debug(command, args)
+ if command == "begin" {
+ assertEq(c.tx, nil, "no running transactions")
+ c.tx = c.db.newTransaction()
+ c.db.assertValidTransaction(c.tx)
+ return fmt.Sprintf("%d", c.tx.id), nil
+ }
+
// TODO
return "", fmt.Errorf("unimplemented")
}
To abort a transaction, we call the completeTransaction method
(which makes sure the database transaction history gets updated) with
the AbortedTransaction state.
return fmt.Sprintf("%d", c.tx.id), nil
}
+ if command == "abort" {
+ c.db.assertValidTransaction(c.tx)
+ err := c.db.completeTransaction(c.tx, AbortedTransaction)
+ c.tx = nil
+ return "", err
+ }
+
// TODO
return "", fmt.Errorf("unimplemented")
}
And to commit a transaction is similar.
return "", err
}
+ if command == "commit" {
+ c.db.assertValidTransaction(c.tx)
+ err := c.db.completeTransaction(c.tx, CommittedTransaction)
+ c.tx = nil
+ return "", err
+ }
+
// TODO
return "", fmt.Errorf("unimplemented")
}
The neat thing about MVCC is that beginning, committing, and aborting a transaction is metadata work. Committing a transaction will get a bit more complex when we add support for Snapshot Isolation and Serializable Isolation, but we'll get to that later. Even then, it will not involve modifying any values we get, set, or delete.
Get, set, delete
Here is where things get fun. As mentioned earlier, the key-value
store is actually map[string][]Value. With the more recent versions
of a value at the end of the list of values for the key.
For get support, we'll iterate the list of value versions backwards
for the key. And we'll call a special new isvisible method to
determine if this transaction can see this value. The first value that
passes the isvisible test is the correct value for the transaction.
return "", err
}
+ if command == "get" {
+ c.db.assertValidTransaction(c.tx)
+
+ key := args[0]
+
+ c.tx.readset.Insert(key)
+
+ for i := len(c.db.store[key]) - 1; i >= 0; i-- {
+ value := c.db.store[key][i]
+ debug(value, c.tx, c.db.isvisible(c.tx, value))
+ if c.db.isvisible(c.tx, value) {
+ return value.value, nil
+ }
+ }
+
+ return "", fmt.Errorf("cannot get key that does not exist")
+ }
+
// TODO
return "", fmt.Errorf("unimplemented")
}
I snuck in tracking which keys are read, and we'll also soon sneak in tracking which keys are written. This is necessary in stricter isolation levels. More on that later.
set and delete are similar to get. But this time when we walk the
list of value versions, we will set the txEndId for the value to the
current transaction id if the value version is visible to this
transaction.
Then, for set, we'll append to the value version list with the new
version of the value that starts at this current transaction.
return "", err
}
+ if command == "set" || command == "delete" {
+ c.db.assertValidTransaction(c.tx)
+
+ key := args[0]
+
+ // Mark all visible versions as now invalid.
+ found := false
+ for i := len(c.db.store[key]) - 1; i >= 0; i-- {
+ value := &c.db.store[key][i]
+ debug(value, c.tx, c.db.isvisible(c.tx, *value))
+ if c.db.isvisible(c.tx, *value) {
+ value.txEndId = c.tx.id
+ found = true
+ }
+ }
+ if command == "delete" && !found {
+ return "", fmt.Errorf("cannot delete key that does not exist")
+ }
+
+ c.tx.writeset.Insert(key)
+
+ // And add a new version if it's a set command.
+ if command == "set" {
+ value := args[1]
+ c.db.store[key] = append(c.db.store[key], Value{
+ txStartId: c.tx.id,
+ txEndId: 0,
+ value: value,
+ })
+
+ return value, nil
+ }
+
+ // Delete ok.
+ return "", nil
+ }
+
if command == "get" {
c.db.assertValidTransaction(c.tx)
This time rather than modifying the readset we modify the writeset
for the transaction.
And that is how commands get executed!
Let's zoom in to the core of the problem we have mentioned but not implemented: MVCC visibility rules and how they differ by isolation levels.
Isolation levels and MVCC visibility rules
To varying degrees, transaction isolation levels prevent concurrent transactions from messing with each other. The looser isolation levels prevent this almost not at all.
Here is what the 1999 ANSI SQL standard (page 84) has to say.
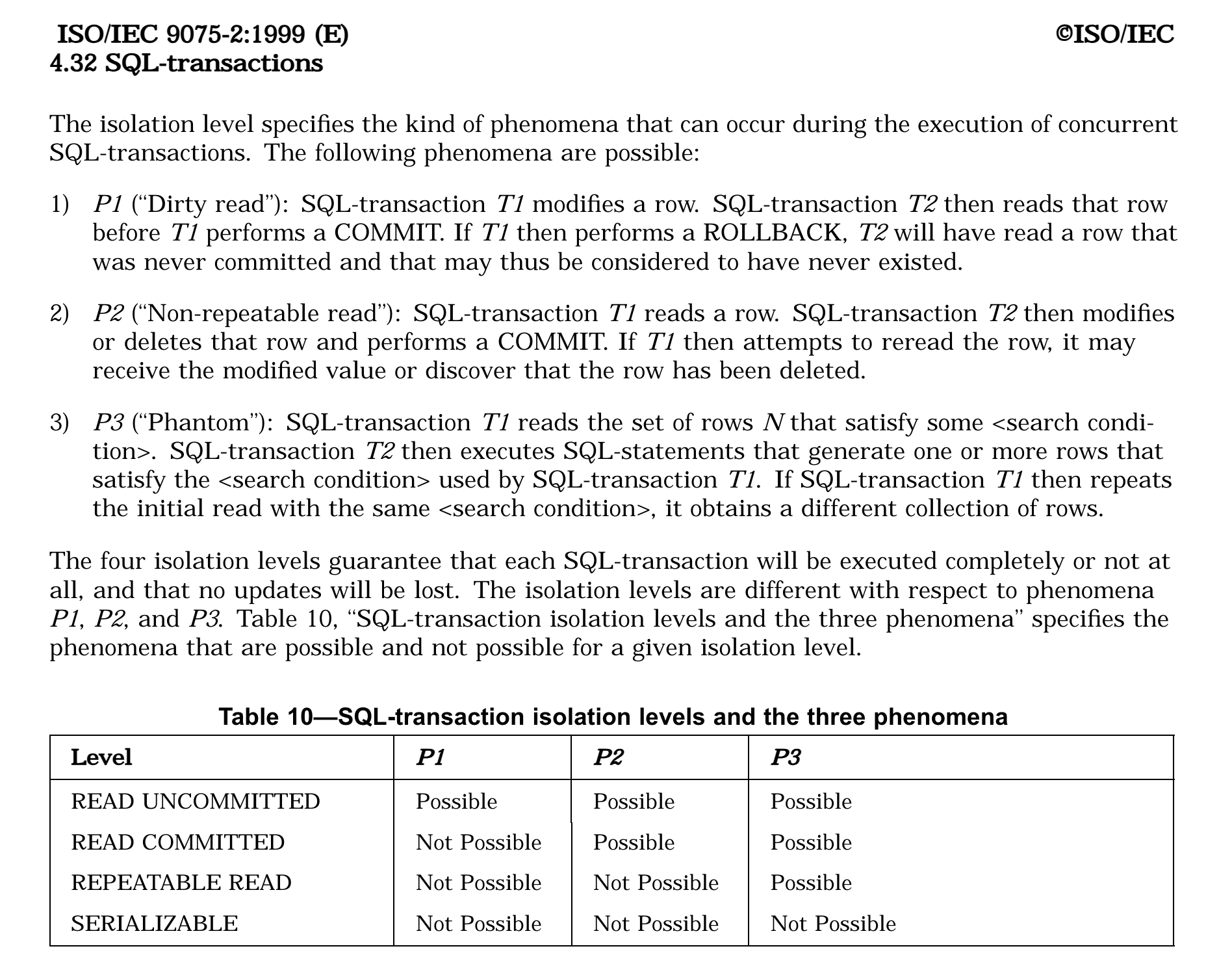
But as I mentioned in the beginning of the post, we're going to be a bit informal. And we'll mostly refer to Jepsen summaries of each isolation levels.
Read Uncommitted
According to Jepsen, the loosest isolation level, Read Uncommitted, has almost no restrictions. We can merely read the most recent (non-deleted) version of a value, regardless of if the transaction that set it has committed or aborted or not.
func (d *Database) isvisible(t *Transaction, value Value) bool {
// Read Uncommitted means we simply read the last value
// written. Even if the transaction that wrote this value has
// not committed, and even if it has aborted.
if t.isolation == ReadUncommittedIsolation {
// We must merely make sure the value has not been
// deleted.
return value.txEndId == 0
}
assert(false, "unsupported isolation level")
return false
}
Let's write a test that demonstrates this. We create two transactions,
c1 and c2, and set a key in c1. The value set for the key in
c1 should be immediately visible if c2 asks for that key. In
main_test.go:
package main
import (
"testing"
)
func TestReadUncommitted(t *testing.T) {
database := newDatabase()
database.defaultIsolation = ReadUncommittedIsolation
c1 := database.newConnection()
c1.mustExecCommand("begin", nil)
c2 := database.newConnection()
c2.mustExecCommand("begin", nil)
c1.mustExecCommand("set", []string{"x", "hey"})
// Update is visible to self.
res := c1.mustExecCommand("get", []string{"x"})
assertEq(res, "hey", "c1 get x")
// But since read uncommitted, also available to everyone else.
res = c2.mustExecCommand("get", []string{"x"})
assertEq(res, "hey", "c2 get x")
// And if we delete, that should be respected.
res = c1.mustExecCommand("delete", []string{"x"})
assertEq(res, "", "c1 delete x")
res, err := c1.execCommand("get", []string{"x"})
assertEq(res, "", "c1 sees no x")
assertEq(err.Error(), "cannot get key that does not exist", "c1 sees no x")
res, err = c2.execCommand("get", []string{"x"})
assertEq(res, "", "c2 sees no x")
assertEq(err.Error(), "cannot get key that does not exist", "c2 sees no x")
}
Thank you to @glaebhoerl for pointing out that in an earlier version of this post, Read Uncommitted incorrectly made deleted values visible.
That's pretty simple! But also pretty useless if your workload has conflicts. If you can arrange your workload in a way where you know no concurrent transactions will ever read or write conflicting keys though, this could be pretty efficient! The rules will only get more complex (and thus potentially more of a bottleneck) from here on.
But for the most part, people don't use this isolation level. SQLite, Yugabyte, Cockroach, and Postgres don't even implement it. It is also not the default for any major database that does implement it.
Let's get a little stricter.
Read Committed
We'll pull again from Jepsen:
Read committed is a consistency model which strengthens read uncommitted by preventing dirty reads: transactions are not allowed to observe writes from transactions which do not commit.
This sounds pretty simple. In isvisible we'll make sure that the
value has a txStartId that is either this transaction or a
transaction that has committed. Moreover we will now begin checking
against txEndId to make sure the value wasn't deleted by any
relevant transaction.
return value.txEndId == 0
}
+ // Read Committed means we are allowed to read any values that
+ // are committed at the point in time where we read.
+ if t.isolation == ReadCommittedIsolation {
+ // If the value was created by a transaction that is
+ // not committed, and not this current transaction,
+ // it's no good.
+ if value.txStartId != t.id &&
+ d.transactionState(value.txStartId).state != CommittedTransaction {
+ return false
+ }
+
+ // If the value was deleted in this transaction, it's no good.
+ if value.txEndId == t.id {
+ return false
+ }
+
+ // Or if the value was deleted in some other committed
+ // transaction, it's no good.
+ if value.txEndId > 0 &&
+ d.transactionState(value.txEndId).state == CommittedTransaction {
+ return false
+ }
+
+ // Otherwise the value is good.
+ return true
+ }
+
assert(false, "unsupported isolation level")
return false
}
This begins to look useful! We will never read a value that isn't part of a committed transaction (or isn't part of our own transaction). Indeed this is the default isolation level for many databases including Postgres, Yugabyte, Oracle, and SQL Server.
Let's add a test to main_test.go. This is a bit long, but give it a
slow read. It is thoroughly commented.
func TestReadCommitted(t *testing.T) {
database := newDatabase()
database.defaultIsolation = ReadCommittedIsolation
c1 := database.newConnection()
c1.mustExecCommand("begin", nil)
c2 := database.newConnection()
c2.mustExecCommand("begin", nil)
// Local change is visible locally.
c1.mustExecCommand("set", []string{"x", "hey"})
res := c1.mustExecCommand("get", []string{"x"})
assertEq(res, "hey", "c1 get x")
// Update not available to this transaction since this is not
// committed.
res, err := c2.execCommand("get", []string{"x"})
assertEq(res, "", "c2 get x")
assertEq(err.Error(), "cannot get key that does not exist", "c2 get x")
c1.mustExecCommand("commit", nil)
// Now that it's been committed, it's visible in c2.
res = c2.mustExecCommand("get", []string{"x"})
assertEq(res, "hey", "c2 get x")
c3 := database.newConnection()
c3.mustExecCommand("begin", nil)
// Local change is visible locally.
c3.mustExecCommand("set", []string{"x", "yall"})
res = c3.mustExecCommand("get", []string{"x"})
assertEq(res, "yall", "c3 get x")
// But not on the other commit, again.
res = c2.mustExecCommand("get", []string{"x"})
assertEq(res, "hey", "c2 get x")
c3.mustExecCommand("abort", nil)
// And still not, if the other transaction aborted.
res = c2.mustExecCommand("get", []string{"x"})
assertEq(res, "hey", "c2 get x")
// And if we delete it, it should show up deleted locally.
c2.mustExecCommand("delete", []string{"x"})
res, err = c2.execCommand("get", []string{"x"})
assertEq(res, "", "c2 get x")
assertEq(err.Error(), "cannot get key that does not exist", "c2 get x")
c2.mustExecCommand("commit", nil)
// It should also show up as deleted in new transactions now
// that it has been committed.
c4 := database.newConnection()
c4.mustExecCommand("begin", nil)
res, err = c4.execCommand("get", []string{"x"})
assertEq(res, "", "c4 get x")
assertEq(err.Error(), "cannot get key that does not exist", "c4 get x")
}
Again this seems great. However! You can easily get inconsistent data within a transaction at this isolation level. If the transaction A has multiple statements it can see different results per statement, even if the transaction A did not modify data. Another transaction B may have committed changes between two statements in this transaction A.
Let's get a little stricter.
Repeatable Read
Again as Jepsen says, Repeatable Read is the same as Read Committed but with the following anomaly not allowed (quoting from the ANSI SQL 1999 standard):
P2 (“Non-repeatable read”): SQL-transaction T1 reads a row. SQL-transaction T2 then modifies or deletes that row and performs a COMMIT. If T1 then attempts to reread the row, it may receive the modified value or discover that the row has been deleted.
To support this, we will add additional checks for the Read Committed logic that make sure the value was not created and not deleted within a transaction that started before this transaction started.
As it happens, this is the same logic that will be necessary for Snapshot Isolation and Serializable Isolation. The additional logic (that makes Snapshot Isolation and Serializable Isolation different) happens at commit time.
return true
}
- assert(false, "unsupported isolation level")
- return false
+ // Repeatable Read, Snapshot Isolation, and Serializable
+ // further restricts Read Committed so only versions from
+ // transactions that completed before this one started are
+ // visible.
+
+ // Snapshot Isolation and Serializable will do additional
+ // checks at commit time.
+ assert(t.isolation == RepeatableReadIsolation ||
+ t.isolation == SnapshotIsolation ||
+ t.isolation == SerializableIsolation, "invalid isolation level")
+ // Ignore values from transactions started after this one.
+ if value.txStartId > t.id {
+ return false
+ }
+
+ // Ignore values created from transactions in progress when
+ // this one started.
+ if t.inprogress.Contains(value.txStartId) {
+ return false
+ }
+
+ // If the value was created by a transaction that is not
+ // committed, and not this current transaction, it's no good.
+ if d.transactionState(value.txStartId).state != CommittedTransaction &&
+ value.txStartId != t.id {
+ return false
+ }
+
+ // If the value was deleted in this transaction, it's no good.
+ if value.txEndId == t.id {
+ return false
+ }
+
+ // Or if the value was deleted in some other committed
+ // transaction that started before this one, it's no good.
+ if value.txEndId < t.id &&
+ value.txEndId > 0 &&
+ d.transactionState(value.txEndId).state == CommittedTransaction &&
+ !t.inprogress.Contains(value.txEndId) {
+ return false
+ }
+
+ return true
}
type Connection struct {
How do I derive these rules? Mostly by writing tests that should pass or fail and seeing what doesn't make sense. I tried to steal from existing projects but these rules were not so simple to discover. Which is part of what I hope makes this project particularly useful to look at.
Let's write a test for Repeatable Read. Again, the test is long but well commented.
func TestRepeatableRead(t *testing.T) {
database := newDatabase()
database.defaultIsolation = RepeatableReadIsolation
c1 := database.newConnection()
c1.mustExecCommand("begin", nil)
c2 := database.newConnection()
c2.mustExecCommand("begin", nil)
// Local change is visible locally.
c1.mustExecCommand("set", []string{"x", "hey"})
res := c1.mustExecCommand("get", []string{"x"})
assertEq(res, "hey", "c1 get x")
// Update not available to this transaction since this is not
// committed.
res, err := c2.execCommand("get", []string{"x"})
assertEq(res, "", "c2 get x")
assertEq(err.Error(), "cannot get key that does not exist", "c2 get x")
c1.mustExecCommand("commit", nil)
// Even after committing, it's not visible in an existing
// transaction.
res, err = c2.execCommand("get", []string{"x"})
assertEq(res, "", "c2 get x")
assertEq(err.Error(), "cannot get key that does not exist", "c2 get x")
// But is available in a new transaction.
c3 := database.newConnection()
c3.mustExecCommand("begin", nil)
res = c3.mustExecCommand("get", []string{"x"})
assertEq(res, "hey", "c3 get x")
// Local change is visible locally.
c3.mustExecCommand("set", []string{"x", "yall"})
res = c3.mustExecCommand("get", []string{"x"})
assertEq(res, "yall", "c3 get x")
// But not on the other commit, again.
res, err = c2.execCommand("get", []string{"x"})
assertEq(res, "", "c2 get x")
assertEq(err.Error(), "cannot get key that does not exist", "c2 get x")
c3.mustExecCommand("abort", nil)
// And still not, regardless of abort, because it's an older
// transaction.
res, err = c2.execCommand("get", []string{"x"})
assertEq(res, "", "c2 get x")
assertEq(err.Error(), "cannot get key that does not exist", "c2 get x")
// And again still the aborted set is still not on a new
// transaction.
c4 := database.newConnection()
res = c4.mustExecCommand("begin", nil)
res = c4.mustExecCommand("get", []string{"x"})
assertEq(res, "hey", "c4 get x")
c4.mustExecCommand("delete", []string{"x"})
c4.mustExecCommand("commit", nil)
// But the delete is visible to new transactions now that this
// has been committed.
c5 := database.newConnection()
res = c5.mustExecCommand("begin", nil)
res, err = c5.execCommand("get", []string{"x"})
assertEq(res, "", "c5 get x")
assertEq(err.Error(), "cannot get key that does not exist", "c5 get x")
}
Let's get stricter!
Snapshot Isolation
Back to Jepsen for a definition:
In a snapshot isolated system, each transaction appears to operate on an independent, consistent snapshot of the database. Its changes are visible only to that transaction until commit time, when all changes become visible atomically to any transaction which begins at a later time. If transaction T1 has modified an object x, and another transaction T2 committed a write to x after T1’s snapshot began, and before T1’s commit, then T1 must abort.
So Snapshot Isolation is the same as Repeatable Read but with one additional rule: the keys written by any two concurrent committed transactions must not overlap.
This is why we tracked writeset. Every time a transaction modified
or deleted a key, we added it to the transaction's writeset. To make
sure we abort correctly, we'll add a conflict check to the commit
step. (This idea is also well documented in A critique of snapshot
isolation. This
paper can be hard to find. Email me if you want a copy.)
When a transaction A goes to commit, it will run a conflict test for any transaction B that has committed since this transaction A started.
Serializable Isolation is going to have a similar check. So we'll add a helper for iterating through all relevant transactions, running a check function for any transaction that has committed.
func (d *Database) hasConflict(t1 *Transaction, conflictFn func(*Transaction, *Transaction) bool) bool {
iter := d.transactions.Iter()
// First see if there is any conflict with transactions that
// were in progress when this one started.
inprogressIter := t1.inprogress.Iter()
for ok := inprogressIter.First(); ok; ok = inprogressIter.Next() {
id := inprogressIter.Key()
found := iter.Seek(id)
if !found {
continue
}
t2 := iter.Value()
if t2.state == CommittedTransaction {
if conflictFn(t1, &t2) {
return true
}
}
}
// Then see if there is any conflict with transactions that
// started and committed after this one started.
for id := t1.id; id < d.nextTransactionId; id++ {
found := iter.Seek(id)
if !found {
continue
}
t2 := iter.Value()
if t2.state == CommittedTransaction {
if conflictFn(t1, &t2) {
return true
}
}
}
return false
}
It was around this point that I decided I did really need a B-Tree implementation and could not just stick to vanilla Go data structures.
Now we can modify completeTransaction to do this check if the
transaction intends to commit. If the current transaction A's write
set intersects with any other transaction B committed since
transaction A started, we must abort.
func (d *Database) completeTransaction(t *Transaction, state TransactionState) error {
debug("completing transaction ", t.id)
+
+ if state == CommittedTransaction {
+ // Snapshot Isolation imposes the additional constraint that
+ // no transaction A may commit after writing any of the same
+ // keys as transaction B has written and committed during
+ // transaction A's life.
+ if t.isolation == SnapshotIsolation && d.hasConflict(t, func(t1 *Transaction, t2 *Transaction) bool {
+ return setsShareItem(t1.writeset, t2.writeset)
+ }) {
+ d.completeTransaction(t, AbortedTransaction)
+ return fmt.Errorf("write-write conflict")
+ }
+ }
+
// Update transactions.
t.state = state
d.transactions.Set(t.id, *t)
Lastly, the definition of setsShareItem.
func setsShareItem(s1 btree.Set[string], s2 btree.Set[string]) bool {
s1Iter := s1.Iter()
s2Iter := s2.Iter()
for ok := s1Iter.First(); ok; ok = s1Iter.Next() {
s1Key := s1Iter.Key()
found := s2Iter.Seek(s1Key)
if found {
return true
}
}
return false
}
Since Snapshot Isolation shares all the same visibility rules as Repeatable Read, the tests get to be a little simpler! We'll simply test that two transactions attempting to commit a write to the same key fail. Or specifically: that the second transaction cannot commit.
func TestSnapshotIsolation_writewrite_conflict(t *testing.T) {
database := newDatabase()
database.defaultIsolation = SnapshotIsolation
c1 := database.newConnection()
c1.mustExecCommand("begin", nil)
c2 := database.newConnection()
c2.mustExecCommand("begin", nil)
c3 := database.newConnection()
c3.mustExecCommand("begin", nil)
c1.mustExecCommand("set", []string{"x", "hey"})
c1.mustExecCommand("commit", nil)
c2.mustExecCommand("set", []string{"x", "hey"})
res, err := c2.execCommand("commit", nil)
assertEq(res, "", "c2 commit")
assertEq(err.Error(), "write-write conflict", "c2 commit")
// But unrelated keys cause no conflict.
c3.mustExecCommand("set", []string{"y", "no conflict"})
c3.mustExecCommand("commit", nil)
}
Not bad! But let's get stricter.
Upon further discussion with Alex Miller, and after reviewing A
Critique of ANSI SQL Isolation Levels, the difference I am
trying to suggest (between Repeatable Read and Snapshot Isolation)
likely does not exist. A Critique of ANSI SQL Isolation Levels
mentions Repeatable Read must not exhibit P4 (Lost Update)
anomalies. And it mentions that you must check for read-write
conflicts to avoid these. Therefore it seems likely that you can't
easily separate Repeatable Read from Snapshot Isolation when
implemented using MVCC. The differences between Repeatable Read and
Snapshot Isolation may more readily show up when implementing
transactions the classical way with Two-Phase Locking.
To reiterate, with MVCC and optimistic concurrency control, correct
implementations of Repeatable Read and Snapshot Isolation do not
seem to be distinguishable. Both require write-write conflict
detection.
Serializable Isolation
In terms of end-result, this is the simplest isolation level to reason about. Serializable Isolation must appear as if only a single transaction were executing at a time. Some systems, like SQLite and TigerBeetle, do Actually Serial Execution where only one transaction runs at a time. But few databases implement Serializable like this because it removes a number of fair concurrent execution histories. For example, two concurrent read-only transactions.
Postgres implements serializability via Serializable Snapshot Isolation. MySQL implements serializability via Two-Phase Locking. FoundationDB implements serializability via sequential timestamp assignment and conflict detection.
But the paper, A critique of snapshot isolation, provides a simple (though not necessarily efficient; I have no clue) approach via what they call Write Snapshot Isolation. In their algorithm, if any two transactions read and write set intersect (but not write and write set intersect), the transaction should be aborted. And this (plus Repeatable Read rules) is sufficient for Serializability.
I leave it to that paper for the proof of correctness. In terms of implementing it though it's quite simple and very similar to the Snapshot Isolation we already mentioned.
Inside of completeTransaction add:
}) {
d.completeTransaction(t, AbortedTransaction)
return fmt.Errorf("write-write conflict")
+ }
+
+ // Serializable Isolation imposes the additional constraint that
+ // no transaction A may commit after reading any of the same
+ // keys as transaction B has written and committed during
+ // transaction A's life, or vice-versa.
+ if t.isolation == SerializableIsolation && d.hasConflict(t, func(t1 *Transaction, t2 *Transaction) bool {
+ return setsShareItem(t1.readset, t2.writeset) ||
+ setsShareItem(t1.writeset, t2.readset)
+ }) {
+ d.completeTransaction(t, AbortedTransaction)
+ return fmt.Errorf("read-write conflict")
}
}
And if we add a test for read-write conflicts:
func TestSerializableIsolation_readwrite_conflict(t *testing.T) {
database := newDatabase()
database.defaultIsolation = SerializableIsolation
c1 := database.newConnection()
c1.mustExecCommand("begin", nil)
c2 := database.newConnection()
c2.mustExecCommand("begin", nil)
c3 := database.newConnection()
c3.mustExecCommand("begin", nil)
c1.mustExecCommand("set", []string{"x", "hey"})
c1.mustExecCommand("commit", nil)
_, err := c2.execCommand("get", []string{"x"})
assertEq(err.Error(), "cannot get key that does not exist", "c2 get x")
res, err := c2.execCommand("commit", nil)
assertEq(res, "", "c2 commit")
assertEq(err.Error(), "read-write conflict", "c2 commit")
// But unrelated keys cause no conflict.
c3.mustExecCommand("set", []string{"y", "no conflict"})
c3.mustExecCommand("commit", nil)
}
We see it work! And that's it for a basic implementation of MVCC and major transaction isolation levels.
Production-quality testing
There are two major projects I'm aware of that help you test transaction implementations: Elle and Hermitage. These are probably where I'd go looking if I were implementing this for real.
This project took me long enough on its own and I felt reasonably comfortable with my tests that the gist of my logic was right that I did not test further. For that reason it surely has bugs.
Vacuuming and cleanup
One of the major things this implementation does not do is cleaning up old data. Eventually, older versions of values will be required by no transactions. They should be removed from the value version array. Similarly, eventually older transactions will be required by no transactions. They should be removed from the database transaction history list.
Even if we had the vacuuming process in place though, what about some extreme use patterns. What if a key's value was always going to be 1GB long. And what if multiple transactions made only small changes to the 1GB data. We'd be duplicating a lot of the value across versions.
It sounds less extreme when thinking about storing rows of data rather than key-value data. If a user has 100 columns and only updates one column a number of times, in our scheme we'd end up storing a ton of duplicate cell data for a row.
This is a real-world issue in Postgres that was called out by Andy Pavlo and the Ottertune folks. It turns out that Postgres alone among major databases stores the entire value for every version. In contrast, other major databases like MySQL store a diff.
Conclusion
This post only begins to demonstrate that database behavior differs quite a bit both in terms of results and in terms of optimizations. Everyone implements the ideas differently and to varying degrees.
Moreover, we have only begun to implement the behavior a real SQL database supports. For example, how do visibility rules and conflict detection work with range queries? What about sub-transactions, and save points? These will have to be covered another time.
Hopefully seeing this simple implementation of MVCC and visibility rules helps to clarify at least some of the basics.
Here's a new post walking through an implementation of MVCC and major SQL transaction isolation levels, in 400 lines of Go code.
— Phil Eaton (@eatonphil) May 16, 2024
These ideas might sound esoteric, but they impact almost every developer using any database.https://t.co/crFKM74R5h pic.twitter.com/o9awTPpvvx