As part of bringing myself up-to-speed after joining TigerBeetle, I wanted some background on how distributed consensus and replicated state machines protocols work. TigerBeetle uses Viewstamped Replication. But I wanted to understand all popular protocols and I decided to start with Raft.
We'll implement two key components of Raft in this post (leader election and log replication). Around 1k lines of Go. It took me around 7 months of sporadic studying to come to (what I hope is) an understanding of the basics.
Disclaimer: I'm not an expert. My implementation isn't yet hooked up to Jepsen. I've run it through a mix of manual and automated tests and it seems generally correct. This is not intended to be used in production. It's just for my education.
All code for this project is available on GitHub.
Let's dig in!
The algorithm
The Raft paper itself is quite readable. Give it a read and you'll get the basic idea.
The gist is that nodes in a cluster conduct elections to pick a leader. Users of the Raft cluster send messages to the leader. The leader passes the message to followers and waits for a majority to store the message. Once the message is committed (majority consensus has been reached), the message is applied to a state machine the user supplies. Followers learn about the latest committed message from the leader and apply each new committed message to their local user-supplied state machine.
There's more to it including reconfiguration and snapshotting, which I won't get into in this post. But you can get the gist of Raft by thinking about 1) leader election and 2) replicated logs powering replicated state machines.
Modeling with state machines and key-value stores
I've written before about how you can build a key-value store on top of Raft. How you can build a SQL database on top of a key-value store. And how you can build a distributed SQL database on top of Raft.
This post will start quite similarly to that first post except for that we won't stop at the Raft layer.
A distributed key-value store
To build on top of the Raft library we'll build, we need to create a state machine and commands that are sent to the state machine.
Our state machine will have two operations: get a value from a key, and set a key to a value.
This will go in cmd/kvapi/main.go.
package main
import (
"bytes"
crypto "crypto/rand"
"encoding/binary"
"fmt"
"log"
"math/rand"
"net/http"
"os"
"strconv"
"strings"
"sync"
"github.com/eatonphil/goraft"
)
type statemachine struct {
db *sync.Map
server int
}
type commandKind uint8
const (
setCommand commandKind = iota
getCommand
)
type command struct {
kind commandKind
key string
value string
}
func (s *statemachine) Apply(cmd []byte) ([]byte, error) {
c := decodeCommand(cmd)
switch c.kind {
case setCommand:
s.db.Store(c.key, c.value)
case getCommand:
value, ok := s.db.Load(c.key)
if !ok {
return nil, fmt.Errorf("Key not found")
}
return []byte(value.(string)), nil
default:
return nil, fmt.Errorf("Unknown command: %x", cmd)
}
return nil, nil
}
But the Raft library we'll build needs to deal with various state machines. So commands passed from the user into the Raft cluster must be serialized to bytes.
func encodeCommand(c command) []byte {
msg := bytes.NewBuffer(nil)
err := msg.WriteByte(uint8(c.kind))
if err != nil {
panic(err)
}
err = binary.Write(msg, binary.LittleEndian, uint64(len(c.key)))
if err != nil {
panic(err)
}
msg.WriteString(c.key)
err = binary.Write(msg, binary.LittleEndian, uint64(len(c.value)))
if err != nil {
panic(err)
}
msg.WriteString(c.value)
return msg.Bytes()
}
And the Apply() function from above needs to be able to decode the
bytes:
func decodeCommand(msg []byte) command {
var c command
c.kind = commandKind(msg[0])
keyLen := binary.LittleEndian.Uint64(msg[1:9])
c.key = string(msg[9 : 9+keyLen])
if c.kind == setCommand {
valLen := binary.LittleEndian.Uint64(msg[9+keyLen : 9+keyLen+8])
c.value = string(msg[9+keyLen+8 : 9+keyLen+8+valLen])
}
return c
}
HTTP API
Now that we've modeled the key-value store as a state machine. Let's build the HTTP endpoints that allow the user to operate the state machine through the Raft cluster.
First, let's implement the set operation. We need to grab the key
and value the user passes in and call Apply() on the Raft
cluster. Calling Apply() on the Raft cluster will eventually call
the Apply() function we just wrote, but not until the message sent
to the Raft cluster is actually replicated.
type httpServer struct {
raft *goraft.Server
db *sync.Map
}
// Example:
//
// curl http://localhost:2020/set?key=x&value=1
func (hs httpServer) setHandler(w http.ResponseWriter, r *http.Request) {
var c command
c.kind = setCommand
c.key = r.URL.Query().Get("key")
c.value = r.URL.Query().Get("value")
_, err := hs.raft.Apply([][]byte{encodeCommand(c)})
if err != nil {
log.Printf("Could not write key-value: %s", err)
http.Error(w, http.StatusText(http.StatusBadRequest), http.StatusBadRequest)
return
}
}
To reiterate, we tell the Raft cluster we want this message
replicated. The message contains the operation type (set) and the
operation details (key and value). These messages are custom to
the state machine we wrote. And they will be interpreted by the state
machine we wrote, on each node in the cluster.
Next we handle get-ing values from the cluster. There are two ways
to do this. We already embed a local copy of the distributed key-value
map. We could just read from that map in the current process. But it
might not be up-to-date or correct. It would be fast to read
though. And convenient for debugging.
But the only correct way to read from a Raft cluster is to pass the read through the log replication too.
So we'll support both.
// Example:
//
// curl http://localhost:2020/get?key=x
// 1
// curl http://localhost:2020/get?key=x&relaxed=true # Skips consensus for the read.
// 1
func (hs httpServer) getHandler(w http.ResponseWriter, r *http.Request) {
var c command
c.kind = getCommand
c.key = r.URL.Query().Get("key")
var value []byte
var err error
if r.URL.Query().Get("relaxed") == "true" {
v, ok := hs.db.Load(c.key)
if !ok {
err = fmt.Errorf("Key not found")
} else {
value = []byte(v.(string))
}
} else {
var results []goraft.ApplyResult
results, err = hs.raft.Apply([][]byte{encodeCommand(c)})
if err == nil {
if len(results) != 1 {
err = fmt.Errorf("Expected single response from Raft, got: %d.", len(results))
} else if results[0].Error != nil {
err = results[0].Error
} else {
value = results[0].Result
}
}
}
if err != nil {
log.Printf("Could not encode key-value in http response: %s", err)
http.Error(w, http.StatusText(http.StatusInternalServerError), http.StatusInternalServerError)
return
}
written := 0
for written < len(value) {
n, err := w.Write(value[written:])
if err != nil {
log.Printf("Could not encode key-value in http response: %s", err)
http.Error(w, http.StatusText(http.StatusInternalServerError), http.StatusInternalServerError)
return
}
written += n
}
}
Main
Now that we've set up our custom state machine and our HTTP API for interacting with the Raft cluster, we'll tie it together with reading configuration from the command-line and actually starting the Raft node and the HTTP API.
type config struct {
cluster []goraft.ClusterMember
index int
id string
address string
http string
}
func getConfig() config {
cfg := config{}
var node string
for i, arg := range os.Args[1:] {
if arg == "--node" {
var err error
node = os.Args[i+2]
cfg.index, err = strconv.Atoi(node)
if err != nil {
log.Fatal("Expected $value to be a valid integer in `--node $value`, got: %s", node)
}
i++
continue
}
if arg == "--http" {
cfg.http = os.Args[i+2]
i++
continue
}
if arg == "--cluster" {
cluster := os.Args[i+2]
var clusterEntry goraft.ClusterMember
for _, part := range strings.Split(cluster, ";") {
idAddress := strings.Split(part, ",")
var err error
clusterEntry.Id, err = strconv.ParseUint(idAddress[0], 10, 64)
if err != nil {
log.Fatal("Expected $id to be a valid integer in `--cluster $id,$ip`, got: %s", idAddress[0])
}
clusterEntry.Address = idAddress[1]
cfg.cluster = append(cfg.cluster, clusterEntry)
}
i++
continue
}
}
if node == "" {
log.Fatal("Missing required parameter: --node $index")
}
if cfg.http == "" {
log.Fatal("Missing required parameter: --http $address")
}
if len(cfg.cluster) == 0 {
log.Fatal("Missing required parameter: --cluster $node1Id,$node1Address;...;$nodeNId,$nodeNAddress")
}
return cfg
}
func main() {
var b [8]byte
_, err := crypto.Read(b[:])
if err != nil {
panic("cannot seed math/rand package with cryptographically secure random number generator")
}
rand.Seed(int64(binary.LittleEndian.Uint64(b[:])))
cfg := getConfig()
var db sync.Map
var sm statemachine
sm.db = &db
sm.server = cfg.index
s := goraft.NewServer(cfg.cluster, &sm, ".", cfg.index)
go s.Start()
hs := httpServer{s, &db}
http.HandleFunc("/set", hs.setHandler)
http.HandleFunc("/get", hs.getHandler)
err = http.ListenAndServe(cfg.http, nil)
if err != nil {
panic(err)
}
}
And that's it for the easy part: a distributed key-value store on top of a Raft cluster.
Next we need to implement Raft.
A Raft server
If we take a look at Figure 2 in the Raft paper, we get an idea for all the state we need to model.
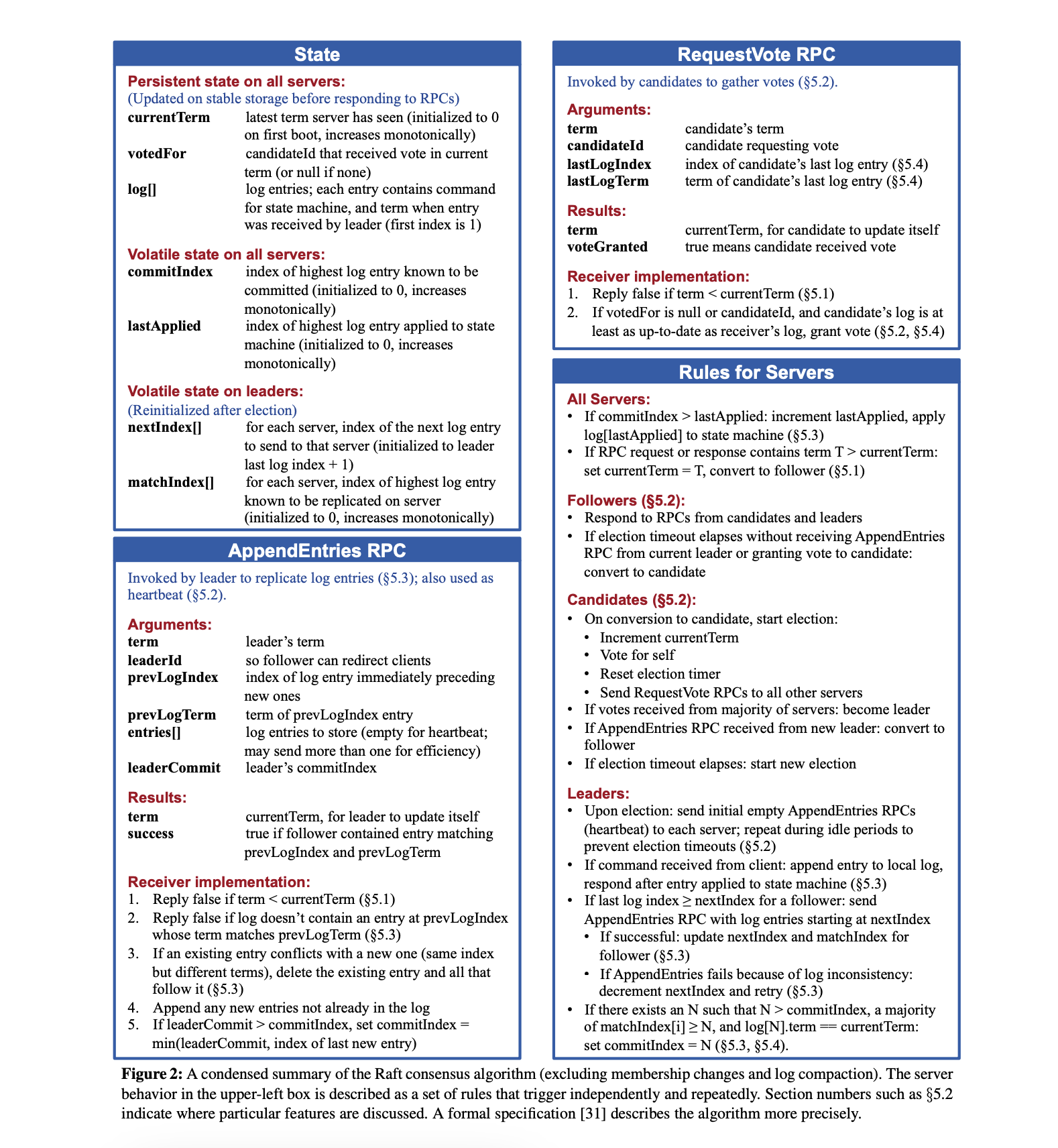
We'll dig into the details as we go. But for now let's turn that model
into a few Go types. This goes in raft.go in the base directory,
not cmd/kvapi.
package goraft
import (
"bufio"
"context"
"encoding/binary"
"errors"
"fmt"
"io"
"math/rand"
"net"
"net/http"
"net/rpc"
"os"
"path"
"sync"
"time"
)
type StateMachine interface {
Apply(cmd []byte) ([]byte, error)
}
type ApplyResult struct {
Result []byte
Error error
}
type Entry struct {
Command []byte
Term uint64
// Set by the primary so it can learn about the result of
// applying this command to the state machine
result chan ApplyResult
}
type ClusterMember struct {
Id uint64
Address string
// Index of the next log entry to send
nextIndex uint64
// Highest log entry known to be replicated
matchIndex uint64
// Who was voted for in the most recent term
votedFor uint64
// TCP connection
rpcClient *rpc.Client
}
type ServerState string
const (
leaderState ServerState = "leader"
followerState = "follower"
candidateState = "candidate"
)
type Server struct {
// These variables for shutting down.
done bool
server *http.Server
Debug bool
mu sync.Mutex
// ----------- PERSISTENT STATE -----------
// The current term
currentTerm uint64
log []Entry
// votedFor is stored in `cluster []ClusterMember` below,
// mapped by `clusterIndex` below
// ----------- READONLY STATE -----------
// Unique identifier for this Server
id uint64
// The TCP address for RPC
address string
// When to start elections after no append entry messages
electionTimeout time.Time
// How often to send empty messages
heartbeatMs int
// When to next send empty message
heartbeatTimeout time.Time
// User-provided state machine
statemachine StateMachine
// Metadata directory
metadataDir string
// Metadata store
fd *os.File
// ----------- VOLATILE STATE -----------
// Index of highest log entry known to be committed
commitIndex uint64
// Index of highest log entry applied to state machine
lastApplied uint64
// Candidate, follower, or leader
state ServerState
// Servers in the cluster, including this one
cluster []ClusterMember
// Index of this server
clusterIndex int
}
And let's build a constructor to initialize the state for all servers in the cluster, as well as local server state.
func NewServer(
clusterConfig []ClusterMember,
statemachine StateMachine,
metadataDir string,
clusterIndex int,
) *Server {
// Explicitly make a copy of the cluster because we'll be
// modifying it in this server.
var cluster []ClusterMember
for _, c := range clusterConfig {
if c.Id == 0 {
panic("Id must not be 0.")
}
cluster = append(cluster, c)
}
return &Server{
id: cluster[clusterIndex].Id,
address: cluster[clusterIndex].Address,
cluster: cluster,
statemachine: statemachine,
metadataDir: metadataDir,
clusterIndex: clusterIndex,
heartbeatMs: 300,
mu: sync.Mutex{},
}
}
And add a few debugging and assertion helpers.
func (s *Server) debugmsg(msg string) string {
return fmt.Sprintf("%s [Id: %d, Term: %d] %s", time.Now().Format(time.RFC3339Nano), s.id, s.currentTerm, msg)
}
func (s *Server) debug(msg string) {
if !s.Debug {
return
}
fmt.Println(s.debugmsg(msg))
}
func (s *Server) debugf(msg string, args ...any) {
if !s.Debug {
return
}
s.debug(fmt.Sprintf(msg, args...))
}
func (s *Server) warn(msg string) {
fmt.Println("[WARN] " + s.debugmsg(msg))
}
func (s *Server) warnf(msg string, args ...any) {
fmt.Println(fmt.Sprintf(msg, args...))
}
func Assert[T comparable](msg string, a, b T) {
if a != b {
panic(fmt.Sprintf("%s. Got a = %#v, b = %#v", msg, a, b))
}
}
func Server_assert[T comparable](s *Server, msg string, a, b T) {
Assert(s.debugmsg(msg), a, b)
}
Persistent state
As Figure 2 says, currentTerm, log, and votedFor must be
persisted to disk as they're edited.
I like to initially doing the stupidest thing possible. So in the
first version of this project I used encoding/gob to write these
three fields to disk every time s.persist() was called.
Here is what this first version looked like:
func (s *Server) persist() {
s.mu.Lock()
defer s.mu.Unlock()
s.fd.Truncate(0)
s.fd.Seek(0, 0)
enc := gob.NewEncoder(s.fd)
err := enc.Encode(PersistentState{
CurrentTerm: s.currentTerm,
Log: s.log,
VotedFor: s.votedFor,
})
if err != nil {
panic(err)
}
if err = s.fd.Sync(); err != nil {
panic(err)
}
s.debug(fmt.Sprintf("Persisted. Term: %d. Log Len: %d. Voted For: %s.", s.currentTerm, len(s.log), s.votedFor))
}
But doing so means this implementation is a function of the size of the log. And that was horrible for throughput.
I also noticed that encoding/gob is pretty inefficient.
For a simple struct like:
type X struct {
A uint64
B []uint64
C bool
}
encoding/gob uses 68 bytes to store that data for when B has two
entries. If we wrote the
encoder/decoder ourselves we could store that struct in 33 bytes (8
(sizeof(A)) + 8 (sizeof(len(B))) + 16 (len(B) * sizeof(B)) + 1
(sizeof(C))).
It's not that encoding/gob is bad. It just likely has different
constraints than we are party to.
So I decided to swap out encoding/gob for simply binary encoding the
fields and also, importantly, keeping track of exactly how many
entries in the log must be written and only writing that many.
s.persist()
Here's what that looks like.
const PAGE_SIZE = 4096
const ENTRY_HEADER = 16
const ENTRY_SIZE = 128
// Must be called within s.mu.Lock()
func (s *Server) persist(writeLog bool, nNewEntries int) {
t := time.Now()
if nNewEntries == 0 && writeLog {
nNewEntries = len(s.log)
}
s.fd.Seek(0, 0)
var page [PAGE_SIZE]byte
// Bytes 0 - 8: Current term
// Bytes 8 - 16: Voted for
// Bytes 16 - 24: Log length
// Bytes 4096 - N: Log
binary.LittleEndian.PutUint64(page[:8], s.currentTerm)
binary.LittleEndian.PutUint64(page[8:16], s.getVotedFor())
binary.LittleEndian.PutUint64(page[16:24], uint64(len(s.log)))
n, err := s.fd.Write(page[:])
if err != nil {
panic(err)
}
Server_assert(s, "Wrote full page", n, PAGE_SIZE)
if writeLog && nNewEntries > 0 {
newLogOffset := max(len(s.log)-nNewEntries, 0)
s.fd.Seek(int64(PAGE_SIZE+ENTRY_SIZE*newLogOffset), 0)
bw := bufio.NewWriter(s.fd)
var entryBytes [ENTRY_SIZE]byte
for i := newLogOffset; i < len(s.log); i++ {
// Bytes 0 - 8: Entry term
// Bytes 8 - 16: Entry command length
// Bytes 16 - ENTRY_SIZE: Entry command
if len(s.log[i].Command) > ENTRY_SIZE-ENTRY_HEADER {
panic(fmt.Sprintf("Command is too large (%d). Must be at most %d bytes.", len(s.log[i].Command), ENTRY_SIZE-ENTRY_HEADER))
}
binary.LittleEndian.PutUint64(entryBytes[:8], s.log[i].Term)
binary.LittleEndian.PutUint64(entryBytes[8:16], uint64(len(s.log[i].Command)))
copy(entryBytes[16:], []byte(s.log[i].Command))
n, err := bw.Write(entryBytes[:])
if err != nil {
panic(err)
}
Server_assert(s, "Wrote full page", n, ENTRY_SIZE)
}
err = bw.Flush()
if err != nil {
panic(err)
}
}
if err = s.fd.Sync(); err != nil {
panic(err)
}
s.debugf("Persisted in %s. Term: %d. Log Len: %d (%d new). Voted For: %d.", time.Now().Sub(t), s.currentTerm, len(s.log), nNewEntries, s.getVotedFor())
}
Again the important thing is that only the entries that need to be
written are written. We do that by seek-ing to the offset of the
first entry that needs to be written.
And we collect writes of entries in a bufio.Writer so we don't waste
write syscalls. Don't forget to flush the buffered writer!
And don't forget to flush all writes to disk with fd.Sync().
ENTRY_SIZE is something that I could see being configurable based
on the workload. Some workloads truly need only 128 bytes. But a
key-value store probably wants much more than that. This
implementation doesn't try to handle the case of completely
arbitrary sized keys and values.
Lastly, a few helpers used in there:
func min[T ~int | ~uint64](a, b T) T {
if a < b {
return a
}
return b
}
func max[T ~int | ~uint64](a, b T) T {
if a > b {
return a
}
return b
}
// Must be called within s.mu.Lock()
func (s *Server) getVotedFor() uint64 {
for i := range s.cluster {
if i == s.clusterIndex {
return s.cluster[i].votedFor
}
}
Server_assert(s, "Invalid cluster", true, false)
return 0
}
s.restore()
Now let's do the reverse operation, restoring from disk. This will only be called once on startup.
func (s *Server) restore() {
s.mu.Lock()
defer s.mu.Unlock()
if s.fd == nil {
var err error
s.fd, err = os.OpenFile(
path.Join(s.metadataDir, fmt.Sprintf("md_%d.dat", s.id)),
os.O_SYNC|os.O_CREATE|os.O_RDWR,
0755)
if err != nil {
panic(err)
}
}
s.fd.Seek(0, 0)
// Bytes 0 - 8: Current term
// Bytes 8 - 16: Voted for
// Bytes 16 - 24: Log length
// Bytes 4096 - N: Log
var page [PAGE_SIZE]byte
n, err := s.fd.Read(page[:])
if err == io.EOF {
s.ensureLog()
return
} else if err != nil {
panic(err)
}
Server_assert(s, "Read full page", n, PAGE_SIZE)
s.currentTerm = binary.LittleEndian.Uint64(page[:8])
s.setVotedFor(binary.LittleEndian.Uint64(page[8:16]))
lenLog := binary.LittleEndian.Uint64(page[16:24])
s.log = nil
if lenLog > 0 {
s.fd.Seek(int64(PAGE_SIZE), 0)
var e Entry
for i := 0; uint64(i) < lenLog; i++ {
var entryBytes [ENTRY_SIZE]byte
n, err := s.fd.Read(entryBytes[:])
if err != nil {
panic(err)
}
Server_assert(s, "Read full entry", n, ENTRY_SIZE)
// Bytes 0 - 8: Entry term
// Bytes 8 - 16: Entry command length
// Bytes 16 - ENTRY_SIZE: Entry command
e.Term = binary.LittleEndian.Uint64(entryBytes[:8])
lenValue := binary.LittleEndian.Uint64(entryBytes[8:16])
e.Command = entryBytes[16 : 16+lenValue]
s.log = append(s.log, e)
}
}
s.ensureLog()
}
And a few helpers it calls:
func (s *Server) ensureLog() {
if len(s.log) == 0 {
// Always has at least one log entry.
s.log = append(s.log, Entry{})
}
}
// Must be called within s.mu.Lock()
func (s *Server) setVotedFor(id uint64) {
for i := range s.cluster {
if i == s.clusterIndex {
s.cluster[i].votedFor = id
return
}
}
Server_assert(s, "Invalid cluster", true, false)
}
The main loop
Now let's think about the main loop. Before starting the loop we need to 1) restore persistent state from disk and 2) kick off an RPC server so servers in the cluster can send and receive messages to and from eachother.
// Make sure rand is seeded
func (s *Server) Start() {
s.mu.Lock()
s.state = followerState
s.done = false
s.mu.Unlock()
s.restore()
rpcServer := rpc.NewServer()
rpcServer.Register(s)
l, err := net.Listen("tcp", s.address)
if err != nil {
panic(err)
}
mux := http.NewServeMux()
mux.Handle(rpc.DefaultRPCPath, rpcServer)
s.server = &http.Server{Handler: mux}
go s.server.Serve(l)
go func() {
s.mu.Lock()
s.resetElectionTimeout()
s.mu.Unlock()
for {
s.mu.Lock()
if s.done {
s.mu.Unlock()
return
}
state := s.state
s.mu.Unlock()
In the main loop we are either in the leader state, follower state or candidate state.
All states will potentially receive RPC messages from other servers in the cluster but that won't be modeled in this main loop.
The only thing going on in the main loop is that:
- We send heartbeat RPCs (leader state)
- We try to advance the commit index (leader state only) and apply commands to the state machine (leader and follower states)
- We trigger a new election if we haven't received a message in some time (candidate and follower states)
- Or we become the leader (candidate state)
switch state {
case leaderState:
s.heartbeat()
s.advanceCommitIndex()
case followerState:
s.timeout()
s.advanceCommitIndex()
case candidateState:
s.timeout()
s.becomeLeader()
}
}
}()
}
Let's deal with leader election first.
Leader election
Leader election happens every time nodes haven't received a message from a valid leader in some time.
I'll break this up into four major pieces:
- Timing out and becoming a candidate after a random (but bounded)
period of time of not hearing a message from a valid leader:
s.timeout(). - The candidate requests votes from all other servers:
s.requestVote(). - All servers handle vote requests:
s.HandleRequestVoteRequest(). - A candidate with a quorum of vote requests becomes the leader:
s.becomeLeader().
You increment currentTerm, vote for yourself and send RPC vote
requests to other nodes in the server.
func (s *Server) resetElectionTimeout() {
interval := time.Duration(rand.Intn(s.heartbeatMs*2) + s.heartbeatMs*2)
s.debugf("New interval: %s.", interval*time.Millisecond)
s.electionTimeout = time.Now().Add(interval * time.Millisecond)
}
func (s *Server) timeout() {
s.mu.Lock()
defer s.mu.Unlock()
hasTimedOut := time.Now().After(s.electionTimeout)
if hasTimedOut {
s.debug("Timed out, starting new election.")
s.state = candidateState
s.currentTerm++
for i := range s.cluster {
if i == s.clusterIndex {
s.cluster[i].votedFor = s.id
} else {
s.cluster[i].votedFor = 0
}
}
s.resetElectionTimeout()
s.persist(false, 0)
s.requestVote()
}
}
Everything in there is implemented already except for
s.requestVote(). Let's dig into that.
s.requestVote()
By referring back to Figure 2 from the Raft paper we can see how to model the request vote request and response. Let's turn that into some Go types.
type RPCMessage struct {
Term uint64
}
type RequestVoteRequest struct {
RPCMessage
// Candidate requesting vote
CandidateId uint64
// Index of candidate's last log entry
LastLogIndex uint64
// Term of candidate's last log entry
LastLogTerm uint64
}
type RequestVoteResponse struct {
RPCMessage
// True means candidate received vote
VoteGranted bool
}
Now we just need to fill the RequestVoteRequest struct out and send
it to each other node in the cluster in parallel. As we iterate
through nodes in the cluster, we skip ourselves (we always immediately
vote for ourselves).
func (s *Server) requestVote() {
for i := range s.cluster {
if i == s.clusterIndex {
continue
}
go func(i int) {
s.mu.Lock()
s.debugf("Requesting vote from %d.", s.cluster[i].Id)
lastLogIndex := uint64(len(s.log) - 1)
lastLogTerm := s.log[len(s.log)-1].Term
req := RequestVoteRequest{
RPCMessage: RPCMessage{
Term: s.currentTerm,
},
CandidateId: s.id,
LastLogIndex: lastLogIndex,
LastLogTerm: lastLogTerm,
}
s.mu.Unlock()
var rsp RequestVoteResponse
ok := s.rpcCall(i, "Server.HandleRequestVoteRequest", req, &rsp)
if !ok {
// Will retry later
return
}
Now remember from Figure 2 in the Raft paper that we must always check that the RPC request and response is still valid. If the term of the response is greater than our own term, we must immediately stop processing and revert to follower state.
Otherwise only if the response is still relevant to us at the moment (the response term is the same as the request term) and the request has succeeded do we count the vote.
s.mu.Lock()
defer s.mu.Unlock()
if s.updateTerm(rsp.RPCMessage) {
return
}
dropStaleResponse := rsp.Term != req.Term
if dropStaleResponse {
return
}
if rsp.VoteGranted {
s.debugf("Vote granted by %d.", s.cluster[i].Id)
s.cluster[i].votedFor = s.id
}
}(i)
}
}
And that's it for the candidate side of requesting a vote.
The implementation of s.updateTerm() is simple. It just takes care
of transitioning to follower state if the term of an RPC message is
greater than the node's current term.
// Must be called within a s.mu.Lock()
func (s *Server) updateTerm(msg RPCMessage) bool {
transitioned := false
if msg.Term > s.currentTerm {
s.currentTerm = msg.Term
s.state = followerState
s.setVotedFor(0)
transitioned = true
s.debug("Transitioned to follower")
s.resetElectionTimeout()
s.persist(false, 0)
}
return transitioned
}
And the implementation of s.rpcCall() is a wrapper around net/rpc
to lazily connect.
func (s *Server) rpcCall(i int, name string, req, rsp any) bool {
s.mu.Lock()
c := s.cluster[i]
var err error
var rpcClient *rpc.Client = c.rpcClient
if c.rpcClient == nil {
c.rpcClient, err = rpc.DialHTTP("tcp", c.Address)
rpcClient = c.rpcClient
}
s.mu.Unlock()
// TODO: where/how to reconnect if the connection must be reestablished?
if err == nil {
err = rpcClient.Call(name, req, rsp)
}
if err != nil {
s.warnf("Error calling %s on %d: %s.", name, c.Id, err)
}
return err == nil
}
Let's dig into the other side of request vote, what happens when a node receives a vote request?
s.HandleVoteRequest()
First off, as discussed above, we must always check the RPC term versus our own and revert to follower if the term is greater than our own. (Remember that since this is an RPC request it could come to a server in any state: leader, candidate, or follower.)
func (s *Server) HandleRequestVoteRequest(req RequestVoteRequest, rsp *RequestVoteResponse) error {
s.mu.Lock()
defer s.mu.Unlock()
s.updateTerm(req.RPCMessage)
s.debugf("Received vote request from %d.", req.CandidateId)
Then we can return immediately if the request term is lower than our own (that means it's an old request).
rsp.VoteGranted = false
rsp.Term = s.currentTerm
if req.Term < s.currentTerm {
s.debugf("Not granting vote request from %d.", req.CandidateId)
Server_assert(s, "VoteGranted = false", rsp.VoteGranted, false)
return nil
}
And finally, we check to make sure the requester's log is at least as up-to-date as our own and that we haven't already voted for ourselves.
The first condition (up-to-date log) was not described in the Raft paper that I could find. But the author of the paper published a Raft TLA+ spec that does have it defined.
And the second condition you might think could never happen since we already wrote the code that said when we trigger an election we vote for ourselves. But since each server has a random election timeout, the one who starts the election will differ in timing sufficiently enough to catch other servers and allow them to vote for it.
lastLogTerm := s.log[len(s.log)-1].Term
logLen := uint64(len(s.log) - 1)
logOk := req.LastLogTerm > lastLogTerm ||
(req.LastLogTerm == lastLogTerm && req.LastLogIndex >= logLen)
grant := req.Term == s.currentTerm &&
logOk &&
(s.getVotedFor() == 0 || s.getVotedFor() == req.CandidateId)
if grant {
s.debugf("Voted for %d.", req.CandidateId)
s.setVotedFor(req.CandidateId)
rsp.VoteGranted = true
s.resetElectionTimeout()
s.persist(false, 0)
} else {
s.debugf("Not granting vote request from %d.", +req.CandidateId)
}
return nil
}
Lastly, we need to address how the candidate who sent out vote requests actually becomes the leader.
s.becomeLeader()
This is a relatively simple method. If we have a quorum of votes, we become the leader!
func (s *Server) becomeLeader() {
s.mu.Lock()
defer s.mu.Unlock()
quorum := len(s.cluster)/2 + 1
for i := range s.cluster {
if s.cluster[i].votedFor == s.id && quorum > 0 {
quorum--
}
}
There is a bit of bookkeeping we need to do like resetting nextIndex
and matchIndex for each server (noted in Figure 2). And we also need
to append a blank entry for the new term.
Despite the section quoted below in code, I still don't understand why this blank entry is necessary.
if quorum == 0 {
// Reset all cluster state
for i := range s.cluster {
s.cluster[i].nextIndex = uint64(len(s.log) + 1)
// Yes, even matchIndex is reset. Figure 2
// from Raft shows both nextIndex and
// matchIndex are reset after every election.
s.cluster[i].matchIndex = 0
}
s.debug("New leader.")
s.state = leaderState
// From Section 8 Client Interaction:
// > First, a leader must have the latest information on
// > which entries are committed. The Leader
// > Completeness Property guarantees that a leader has
// > all committed entries, but at the start of its
// > term, it may not know which those are. To find out,
// > it needs to commit an entry from its term. Raft
// > handles this by having each leader commit a blank
// > no-op entry into the log at the start of its term.
s.log = append(s.log, Entry{Term: s.currentTerm, Command: nil})
s.persist(true, 1)
// Triggers s.appendEntries() in the next tick of the
// main state loop.
s.heartbeatTimeout = time.Now()
}
}
And we're done with elections!
When I was working on this for the first time, I just stopped here and made sure I could get to a stable leader quickly. If it takes more than 1 term to establish a leader when you run three servers in the cluster on localhost, you've probably got a bug.
In an ideal environment (which three processes on one machine most likely is), leadership should be established quite quickly and without many term changes. As the environment gets more adversarial (e.g. processes crash frequently or network latency is high and variable), leadership (and log replication) will take longer.
But just because we have leader election working when there are no
logs does not mean we'll have it working when we introduce log
replication since parts of voting depend on log analysis.
I had leader election working at one time but then it broke when I
got log replication working until I found some more bugs in leader
election and fixed them. Of course, there may still be bugs even
now.
Log replication
I'll break up log replication into four major pieces:
- User submits a message to the leader to be replicated:
s.Apply(). - The leader sends uncommitted messages (messages from
nextIndex) to all followers:s.appendEntries(). - A follower receives a
AppendEntriesRequestand stores new messages if appropriate, letting the leader know when it does store the messages:s.HandleAppendEntriesRequest(). - The leader tries to update
commitIndexfor the last uncommitted message by seeing if it's been replicated on a quorum of servers:s.advanceCommitIndex().
Let's dig in in that order.
s.Apply()
This is the entry point for a user of the cluster to attempt to get messages replicated into the cluster.
It must be called on the current leader of the cluster. In the future
the failure response might include the current leader. Or the user
could submit messages in parallel to all nodes in the cluster and
ignore ErrApplyToLeader. In the meantime we just assume the user can
figure out which server in the cluster is the leader.
var ErrApplyToLeader = errors.New("Cannot apply message to follower, apply to leader.")
func (s *Server) Apply(commands [][]byte) ([]ApplyResult, error) {
s.mu.Lock()
if s.state != leaderState {
s.mu.Unlock()
return nil, ErrApplyToLeader
}
s.debugf("Processing %d new entry!", len(commands))
Next we'll store the message in the leader's log along with a Go channel that we must block on for the result of applying the message in the state machine after the message has been committed to the cluster.
resultChans := make([]chan ApplyResult, len(commands))
for i, command := range commands {
resultChans[i] = make(chan ApplyResult)
s.log = append(s.log, Entry{
Term: s.currentTerm,
Command: command,
result: resultChans[i],
})
}
s.persist(true, len(commands))
Then we kick off the replication process (this will not block).
s.debug("Waiting to be applied!")
s.mu.Unlock()
s.appendEntries()
And then we block until we receive results from each of the channels we created.
// TODO: What happens if this takes too long?
results := make([]ApplyResult, len(commands))
var wg sync.WaitGroup
wg.Add(len(commands))
for i, ch := range resultChans {
go func(i int, c chan ApplyResult) {
results[i] = <-c
wg.Done()
}(i, ch)
}
wg.Wait()
return results, nil
}
The interesting thing here is that appending entries is detached from
the messages we just received. s.appendEntries() will probably
include at least the messages we just appended to our log, but it
might include more too if some servers are not very up-to-date. It may
even include less than the messages we append to our log since we'll
restrict the number of entries to send at one time so we keep latency
down.
s.appendEntries()
This is the meat of log replication on the leader side. We send unreplicated messages to each other server in the cluster.
By again referring back to Figure 2 from the Raft paper we can see how to model the request vote request and response. Let's turn that into some Go types too.
type AppendEntriesRequest struct {
RPCMessage
// So follower can redirect clients
LeaderId uint64
// Index of log entry immediately preceding new ones
PrevLogIndex uint64
// Term of prevLogIndex entry
PrevLogTerm uint64
// Log entries to store. Empty for heartbeat.
Entries []Entry
// Leader's commitIndex
LeaderCommit uint64
}
type AppendEntriesResponse struct {
RPCMessage
// true if follower contained entry matching prevLogIndex and
// prevLogTerm
Success bool
}
For the method itself, we start optimistically sending no entries and
decrement nextIndex for each server as the server fails to replicate
messages. This means that we might eventually end up sending the
entire log to one or all servers.
We'll set a max number of entries to send per request so we avoid
unbounded latency as followers store entries to disk. But we still
want to send a large batch so that we amortize the cost of fsync.
const MAX_APPEND_ENTRIES_BATCH = 8_000
func (s *Server) appendEntries() {
for i := range s.cluster {
// Don't need to send message to self
if i == s.clusterIndex {
continue
}
go func(i int) {
s.mu.Lock()
next := s.cluster[i].nextIndex
prevLogIndex := next - 1
prevLogTerm := s.log[prevLogIndex].Term
var entries []Entry
if uint64(len(s.log)-1) >= s.cluster[i].nextIndex {
s.debugf("len: %d, next: %d, server: %d", len(s.log), next, s.cluster[i].Id)
entries = s.log[next:]
}
// Keep latency down by only applying N at a time.
if len(entries) > MAX_APPEND_ENTRIES_BATCH {
entries = entries[:MAX_APPEND_ENTRIES_BATCH]
}
lenEntries := uint64(len(entries))
req := AppendEntriesRequest{
RPCMessage: RPCMessage{
Term: s.currentTerm,
},
LeaderId: s.cluster[s.clusterIndex].Id,
PrevLogIndex: prevLogIndex,
PrevLogTerm: prevLogTerm,
Entries: entries,
LeaderCommit: s.commitIndex,
}
s.mu.Unlock()
var rsp AppendEntriesResponse
s.debugf("Sending %d entries to %d for term %d.", len(entries), s.cluster[i].Id, req.Term)
ok := s.rpcCall(i, "Server.HandleAppendEntriesRequest", req, &rsp)
if !ok {
// Will retry next tick
return
}
Now, as with every RPC request and response, we must check terms and potentially drop the message if it's outdated.
s.mu.Lock()
defer s.mu.Unlock()
if s.updateTerm(rsp.RPCMessage) {
return
}
dropStaleResponse := rsp.Term != req.Term && s.state == leaderState
if dropStaleResponse {
return
}
Otherwise, if the message was successful, we'll update matchIndex
(the last confirmed message stored on the follower) and nextIndex
(the next likely message to send to the follower).
If the message was not successful, we decrement nextIndex. Next time
s.appendEntries() is called it will include one more previous
message for this replica.
if rsp.Success {
prev := s.cluster[i].nextIndex
s.cluster[i].nextIndex = max(req.PrevLogIndex+lenEntries+1, 1)
s.cluster[i].matchIndex = s.cluster[i].nextIndex - 1
s.debugf("Message accepted for %d. Prev Index: %d, Next Index: %d, Match Index: %d.", s.cluster[i].Id, prev, s.cluster[i].nextIndex, s.cluster[i].matchIndex)
} else {
s.cluster[i].nextIndex = max(s.cluster[i].nextIndex-1, 1)
s.debugf("Forced to go back to %d for: %d.", s.cluster[i].nextIndex, s.cluster[i].Id)
}
}(i)
}
}
And we're done the leader side of append entries!
s.HandleAppendEntriesRequest()
Now for the follower side of log replication. This is, again, an RPC
handler that could be called at any moment. So we need to potentially
update the term (and transition to follower).
func (s *Server) HandleAppendEntriesRequest(req AppendEntriesRequest, rsp *AppendEntriesResponse) error {
s.mu.Lock()
defer s.mu.Unlock()
s.updateTerm(req.RPCMessage)
"Hidden" in the "Candidates (§5.2):" section of Figure 2 is an additional rule about:
If AppendEntries RPC received from new leader: convert to follower
So we also need to handle that here. And if we're still not a follower, we'll return immediately.
// From Candidates (§5.2) in Figure 2
// If AppendEntries RPC received from new leader: convert to follower
if req.Term == s.currentTerm && s.state == candidateState {
s.state = followerState
}
rsp.Term = s.currentTerm
rsp.Success = false
if s.state != followerState {
s.debugf("Non-follower cannot append entries.")
return nil
}
Next, we also return early if the request term is less than our own. This would represent an old request.
if req.Term < s.currentTerm {
s.debugf("Dropping request from old leader %d: term %d.", req.LeaderId, req.Term)
// Not a valid leader.
return nil
}
Now, finally, we know we're receiving a request from a valid leader. So we need to immediately bump the election timeout.
// Valid leader so reset election.
s.resetElectionTimeout()
Then we do the log comparison to see if we can add the entries sent
from this request. Specifically, we make sure that our log at
req.PrevLogIndex exists and has the same term as req.PrevLogTerm.
logLen := uint64(len(s.log))
validPreviousLog := req.PrevLogIndex == 0 /* This is the induction step */ ||
(req.PrevLogIndex < logLen &&
s.log[req.PrevLogIndex].Term == req.PrevLogTerm)
if !validPreviousLog {
s.debug("Not a valid log.")
return nil
}
Next, we've got valid entries that we need to add to our log. This
implementation is a little more complex because we'll make use of Go
slice capacity so that append() never allocates.
Importantly, we must truncate the log if a new entry ever conflicts with an existing one:
If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it (§5.3)
next := req.PrevLogIndex + 1
nNewEntries := 0
for i := next; i < next+uint64(len(req.Entries)); i++ {
e := req.Entries[i-next]
if i >= uint64(cap(s.log)) {
newTotal := next + uint64(len(req.Entries))
// Second argument must actually be `i`
// not `0` otherwise the copy after this
// doesn't work.
// Only copy until `i`, not `newTotal` since
// we'll continue appending after this.
newLog := make([]Entry, i, newTotal*2)
copy(newLog, s.log)
s.log = newLog
}
if i < uint64(len(s.log)) && s.log[i].Term != e.Term {
prevCap := cap(s.log)
// If an existing entry conflicts with a new
// one (same index but different terms),
// delete the existing entry and all that
// follow it (§5.3)
s.log = s.log[:i]
Server_assert(s, "Capacity remains the same while we truncated.", cap(s.log), prevCap)
}
s.debugf("Appending entry: %s. At index: %d.", string(e.Command), len(s.log))
if i < uint64(len(s.log)) {
Server_assert(s, "Existing log is the same as new log", s.log[i].Term, e.Term)
} else {
s.log = append(s.log, e)
Server_assert(s, "Length is directly related to the index.", uint64(len(s.log)), i+1)
nNewEntries++
}
}
Finally, we update the server's local commitIndex to the min of
req.LeaderCommit and our own log length.
And finally we persist all these changes and mark the response as successful.
if req.LeaderCommit > s.commitIndex {
s.commitIndex = min(req.LeaderCommit, uint64(len(s.log)-1))
}
s.persist(nNewEntries != 0, nNewEntries)
rsp.Success = true
return nil
}
So the combined behavior of the leader and follower when replicating is that a follower not in sync with the leader may eventually go down to the beginning of the log so the leader and follower have some first N messages of the log that match.
s.advanceCommitIndex()
Now when not just one follower but a quorum of followers all have a
matching first N messages, the leader can advance the cluster's
commitIndex.
func (s *Server) advanceCommitIndex() {
s.mu.Lock()
defer s.mu.Unlock()
// Leader can update commitIndex on quorum.
if s.state == leaderState {
lastLogIndex := uint64(len(s.log) - 1)
for i := lastLogIndex; i > s.commitIndex; i-- {
quorum := len(s.cluster) / 2 + 1
for j := range s.cluster {
if quorum == 0 {
break
}
isLeader := j == s.clusterIndex
if s.cluster[j].matchIndex >= i || isLeader {
quorum--
}
}
if quorum == 0 {
s.commitIndex = i
s.debugf("New commit index: %d.", i)
break
}
}
}
And for every state a server might be in, if there are messages
committed but not applied, we'll apply one here. And importantly,
we'll pass the result back to the message's result channel if it
exists, so that s.Apply() can learn about the result.
if s.lastApplied <= s.commitIndex {
log := s.log[s.lastApplied]
// len(log.Command) == 0 is a noop committed by the leader.
if len(log.Command) != 0 {
s.debugf("Entry applied: %d.", s.lastApplied)
// TODO: what if Apply() takes too long?
res, err := s.statemachine.Apply(log.Command)
// Will be nil for follower entries and for no-op entries.
// Not nil for all user submitted messages.
if log.result != nil {
log.result <- ApplyResult{
Result: res,
Error: err,
}
}
}
s.lastApplied++
}
}
Heartbeats
Heartbeats combine log replication and leader election. Heartbeats stave off leader election (follower timeouts). And heartbeats also bring followers up-to-date if they are behind.
And it's a simple method. If it's time to heartbeat, we call
s.appendEntries(). That's it.
func (s *Server) heartbeat() {
s.mu.Lock()
defer s.mu.Unlock()
timeForHeartbeat := time.Now().After(s.heartbeatTimeout)
if timeForHeartbeat {
s.heartbeatTimeout = time.Now().Add(time.Duration(s.heartbeatMs) * time.Millisecond)
s.debug("Sending heartbeat")
s.appendEntries()
}
}
The reason this staves off leader election is because any number of entries (0 or N) will come from a valid leader and will thus cause the followers to reset their election timeout.
And that's the entirety of (the basics of) Raft.
There are probably bugs.
Running kvapi
Now let's run the key-value API.
$ cd cmd/kvapi && go build
$ rm *.dat
Terminal 1
$ ./kvapi --node 0 --http :2020 --cluster "0,:3030;1,:3031;2,:3032"
Terminal 2
$ ./kvapi --node 1 --http :2021 --cluster "0,:3030;1,:3031;2,:3032"
Terminal 3
$ ./kvapi --node 2 --http :2022 --cluster "0,:3030;1,:3031;2,:3032"
Terminal 4
Remember that requests will go through the leader (except for if we
turn that off in the /get request). So you'll have to try sending a
message to each server until you find the leader.
To set a key:
$ curl http://localhost:2020/set?key=y&value=hello
To get a key:
$ curl http://localhost:2020/get\?key\=y
And that's that! Try killing a server and restarting it. A new leader will be elected so you'll need to find the right one to send requests to again. But all existing entries should still be there.
A test rig
I won't cover the implementation of my test rig in this post but I will describe it.
It's nowhere near Jepsen but it does have a specific focus:
- Can the cluster elect a leader?
- Can the cluster store logs correctly?
- Can the cluster of three nodes tolerate one node down?
- How fast can it store N messages?
- Are messages recovered correctly when the nodes shut down and start back up?
- If a node's logs are deleted, is the log for that node recovered after it is restarted?
This implementation passes these tests and handles around 20k-40k entries/second.
Considerations
This was quite a challenging project. Normally when I hack on stuff like this I have TV (The Simpsons) on in the background. It's sort of dumb but this was the first project where I absolutely could not focus with that background noise.
There are a tedious number of conditions and I am not sure I got them all (right). Numerous ways for subtle bugs.
Race conditions and deadlocks
It's very easy to program in race conditions. Thankfully Go has the
-race flag that detects this. This makes sure that you are locking
read and write access to shared variables when necessary.
On the other side of race conditions, Go does not help you out with: deadlocks. Once you've got locks in place for shared variables, you need to make sure you're releasing the locks appropriately too.
Thankfully someone wrote a swap-in replacement for the Go sync
package called
go-deadlock. When you import
this package instead of the default sync package, it will panic and
give you a stacktrace when it thinks you hit a deadlock.
Sometimes it thinks you hit a deadlock because a method that needs a
lock takes too long. Sometimes that time it takes is legitimate (or
something you haven't optimized yet). But actually its default of
30s is not really aggressive at all.
So I normally set the deadlock timeout to 2s and eventually would
like to make that more like 100ms:
sync.Opts.DeadlockTimeout = 2000 * time.Millisecond
It's mostly the persist() function that causes go-deadlock to
think there's a deadlock because it tries to synchronously write a
bunch of data to disk.
go-deadlock is slow
The go-deadlock package is incredibly useful. But don't forget to
turn it off for benchmarks. With it on I get around 4-8k
entries/second. With it off I get around 20k-40k entries/second.
Unbounded memory
Another issue in this implementation is that the log keeps growing indefinitely and the entire log is duplicated in memory.
There are two ways to deal with that:
- Implement Raft snapshotting so the log can be truncated safely.
- Keep only some number of entries in memory (say, 1 million) and read from disk as needed when logs need to be verified. In ideal operation this would never happen since ideally all servers are always on, never miss entries, and just keep appending. But "ideal" won't always happen.
Similarly, there is unbounded and unreused channel creation for
notifying s.Apply() when the user-submitted message(s) finish.
net/rpc and encoding/gob
In the persist() section above I already mentioned how I prototyped
this using Go's builtin gob encoding. And I mentioned how inefficient
it was. It's also pretty slow and I learned that because net/rpc
uses it and after everything I did net/rpc started to be the
bottleneck in my benchmarks. This isn't incredibly surprising.
So a future version of this code might implement its own protocol and
own encoding (like we did for disk) on top of TCP rather than use
net/rpc.
Jepsen
Everyone wants to know how a distributed algorithm does against Jepsen, which tests linearizability of distributed systems in the face of network and process faults.
But the setup is not trivial so I haven't hooked it up to this project yet. This would be a good area for future work.
Election timeout and the environment
One thing I noticed as I was trying out alternatives to net/rpc
(alternatives that injected latency to simulate a bad environment) is
that election timeouts should probably be tuned with latency of the
cluster in mind.
If the election timeout is every 300ms but the latency of the
cluster is near 1s, you're going to have non-stop leader election.
When I adjusted the election timeout to be every 2s when the latency
of the cluster is near 1s, everything was fine. Maybe this means
there's a bug in my code but I don't think so.
Client request serial identifier
One major part of the Raft protocol I did not cover is that the client is supposed to send a serial identifier for each message sent to the cluster. This is to ensure that messages are not accidentally duplicated at any level of the entire software stack.
Diego Ongaro's thesis goes into more detail about this than the Raft paper. Search in that PDF for "session".
Again I just completely ignored the possibility of duplicate messages in this implementation so far.
References
Finally, I could not have done this without a bunch of internet help. This project took me about 7 months in total. The first 5 months I was trying to figure it out mostly on my own, just looking at the Raft paper.
The biggest breakthrough came from discovering the author of Raft's TLA+ spec for Raft. Formal methods sound scary but it was truly not too bad! This was the first "implementation" of Raft that was in a single file of code. And under 500 lines.
Jack Vanlightly's guide to reading TLA+ helped a bunch.
Finally, I had to peer at other implementations, especially to figure out locking and avoiding deadlocks.
Here's everything that helped me out.
- In Search of an Understandable Consensus Algorithm: The Raft paper.
- raft.tla: Diego Ongaro's TLA+ spec for Raft.
- Jon Gjengset's Students' Guide to Raft
- Jack Vanlightly's Detecting Bugs in Data Infrastructure using Formal Methods (TLA+ Series Part 1): An intro to TLA+.
And useful implementations I looked at for inspiration and clarity.
- Hashicorp's Raft implementation in Go: Although it's often quite complicated to learn from since it actually is intended for production.
- Eli Bendersky's Raft implementation in Go: Although I got confused following it since it used signed integers and
-1to represent base cases. Signed integers is a fair choice as far as I can tell, I just wanted to only use unsigned integers. - Jing Yang's Raft implementation in Rust: Although I find Rust hard to read.
And I haven't tried these but they look cool:
Cheers!
I wrote about implementing Raft in Go. By far the most challenging project I've worked on in spare time. About 7 months sporadically.
— Phil Eaton (@eatonphil) May 25, 2023
I'm not an expert, and this is not intended to be used in production. I wanted a better background on the subject!https://t.co/EhyBuQ4pD3 pic.twitter.com/vGhBbV1shf