Databases are fun. They sit at the confluence of Computer Science topics that might otherwise not seem practical in life as a developer. For example, every database with a query language is also a programming language implementation of some caliber. That doesn't include all databases though of course; see: RocksDB, FoundationDB, TigerBeetle, etc.
This post looks at how various databases execute expressions in their query language.
tldr; Most surveyed databases use a tree-walking interpreter. A few use stack- or register-based virtual machines. A couple have just-in-time compilers. And, tangentially, a few do vectorized interpretation.
Throughout this post I'll use "virtual machine" as a shorthand for stack- or register-based loops that process a linearized set of instructions. I say this since it is sometimes fair to call a tree-walking interpreter a virtual machine. But that is not what I mean when I say virtual machine in this post.
Stepping back
Programming languages are typically implemented by turning an Abstract Syntax Tree (AST) into a linear set of instructions for a virtual machine (e.g. CPython, Java, C#) or native code (e.g. GCC's C compiler, Go, Rust). Some of the former implementations also generate and run Just-In-Time (JIT) compiled native code (e.g. Java and C#).
Less commonly these days in programming languages does the implementation interpret off the AST or some other tree-like intermediate representation. This style is often called tree-walking.
Shell languages sometimes do tree-walking. Otherwise, implementations that interpret directly off of a tree normally do so as a short-term measure before switching to compiled virtual machine code or JIT-ed native code (e.g. some JavaScript implementations, GraalVM, RPython, etc.)
That is, while some major programming language implementations started out with tree-walking interpreters, they mostly moved away from solely tree-walking over a decade ago. See JSC in 2008, Ruby in 2007, etc.
My intuition is that tree-walking takes up more memory and is less cache-friendly than the linear instructions you give to a virtual machine or to your CPU. There are some folks who disagree, but they mostly talk about tree-walking when you've also got a JIT compiler hooked up. Which isn't quite the same thing. There has also been some early exploration and improvements reported when tree-walking with a tree organized as an array.
And databases?
Databases often interpret directly off a tree. (It isn't, generally speaking, fair to say they are AST-walking interpreters because databases typically transform and optimize beyond just an AST as parsed from user code.)
But not all databases interpret a tree. Some have a virtual machine. And some generate and run JIT-ed native code.
Methodology
If a core function (in the query execution path that does something like arithmetic or comparison) returns a value, that's a sign it's a tree-walking interpreter. Or, if you see code that is evaluating its arguments during execution, that's also a sign of a tree-walking interpreter.
On the other hand, if the function mutates internal state such as by assigning a value to a context or pushing to a stack, that's a sign it's a stack- or register-based virtual machine. If a function pulls its arguments from memory and doesn't evaluate the arguments, that's also an indication it's a stack- or register-based virtual machine.
This approach can result in false-positives depending on the
architecture of the interpreter. User-defined functions (UDFs) would
probably accept evaluated arguments and return a value regardless of
how the interpreter is implemented. So it's important to find not just
functions that could be implemented like UDFs, but core builtin
behavior. Control flow implementations of functions like if or
case can be great places to look.
And tactically, I clone the source code and run stuff like git grep
-i eval | grep -v test | grep \\.java | grep -i eval or git grep -i
expr | grep -v test | grep \\.go | grep -i expr until I convince
myself I'm somewhere interesting.
Note: In talking about a broad swath of projects, maybe I've misunderstood one or some. If you've got a correction, let me know! If there's a proprietary database you work on where you can link to the (publicly described) execution strategy, feel free to pass it along! Or if I'm missing your public-source database in this list, send me a message!
Survey
Cockroach (Ruling: Tree Walker)
Judging by functions like func (e *evaluator)
EvalBinaryExpr
that evaluates the left-hand
side
and then evaluates the right-hand
side
and returns a value, Cockroach looks like a tree walking interpreter.
It gets a little more interesting though, since Cockroach also supports vectorized expression execution. Vectorizing is a fancy term for acting on many pieces of data at once rather than one at a time. It doesn't necessarily imply SIMD. Here is an example of a vectorized addition of two int64 columns.
ClickHouse (Ruling: Tree Walker + JIT)
The ClickHouse architecture is a little unique and difficult for me to read through – likely due to it being fairly mature, with serious optimization. But they tend to document their header files well. So files like src/Functions/IFunction.h and src/Interpreters/ExpressionActions.h were helpful.
They have also spoken publicly about their pipeline execution model; e.g. this presentation and this roadmap issue. But it isn't completely clear how much pipeline execution (which is broader than just expression evaluation) connects to expression evaluation.
Moreover, they have publicly
spoken
about their support for JIT compilation for query execution. But let's
look at how execution works when the JIT is not enabled. For example,
If we take a look at how if is
implemented,
we know that the then and else rows must be conditionally
evaluated.
In the runtime entrypoint,
executeImpl,
we see the function call
executeShortCircuitArguments
which in turn calls
ColumnFunction::reduce()
which evaluates each column vector that is an
argument
to the function and then calls execute on the function.
So from this we can tell the non-JIT execution is a tree walker and that it is over chunks of columns, i.e. vectorized data, similar to Cockroach. However in ClickHouse execution is always over column vectors.
In the original version of this post, I had some confusion about the ClickHouse execution strategy. Robert Schulze from ClickHouse helped clarify things for me. Thanks Robert!
DuckDB (Ruling: Tree Walker)
If we take a look at how function expressions are executed, we can see each argument in the function being evaluated before being passed to the actual function. So that looks like a tree walking interpreter.
Like ClickHouse, DuckDB expression execution is always over column vectors. You can read more about this architecture here and here.
Influx (Ruling: Tree Walker)
Influx originally had a SQL-like query language called InfluxQL. If we look at how it evaluates a binary expression, it first evaluates the left-hand side and then the right-hand side before operating on the sides and returning a value. That's a tree-walking interpreter.
Flux was the new query language for Influx. While the Flux docs suggest they transform to an intermediate representation that is executed on a virtual machine, there's nothing I'm seeing that looks like a stack- or register-based virtual machine. All the evaluation functions evaluate their arguments and return a value. That looks like a tree-walking interpreter to me.
Today Influx announced that Flux is in maintenance mode and they are focusing on InfluxQL again.
MariaDB / MySQL (Ruling: Tree Walker)
Control flow methods are normally a good way to see how an interpreter
is implemented. The implementation of COALESCE looks pretty
simple. We
see it call
val_str()
for each argument to COALESCE. But I can only seem to find
implementations of val_str() on raw values and not
expressions. Item_func_coalesce itself does not implement
val_str() for example, which would be a strong indication of a tree
walker. Maybe it does implement val_str() through inheritance.
It becomes a little clearer if we look at non-control flow methods
like
acos. In
this method we see Item_func_acos itself implement val_real() and
also call val_real() on all its arguments. In this case it's obvious
how the control flow of acos(acos(.5)) would work. So that seems to
indicate expressions are executed with a tree walking interpreter.
I also noticed
sql/sp_instr.cc. That
is scary (in terms of invalidating my analysis) since it looks like a
virtual machine. But after looking through it, I think this virtual
machine only corresponds to how stored procedures are executed, hence
the sp_ prefix for Stored Programs. MySQL
docs
also explain that stored procedures are executed with a bytecode
virtual machine.
I'm curious why they don't use that virtual machine for query execution.
As far as I can tell MySQL and MariaDB do not differ in this regard.
MongoDB (Ruling: Virtual Machine)
Mongo recently introduced a virtual machine for executing queries, called Slot Based Execution (SBE). We can find the SBE code in src/mongo/db/exec/sbe/vm/vm.cpp and the main virtual machine entrypoint here. Looks like a classic stack-based virtual machine!
It isn't completely clear to me if the SBE path is always used or if there are still cases where it falls back to their old execution model. You can read more about Mongo execution here and here.
PostgreSQL (Ruling: Virtual Machine + JIT)
The top of PostgreSQL's src/backend/executor/execExprInterp.c clearly explains that expression execution uses a virtual machine. You see all the hallmarks: opcodes, a loop over a giant switch, etc. And if we look at how function expressions are executed, we see another hallmark which is that the function expression code doesn't evaluate its arguments. They've already been evaluated. And function expression code just acts on the results of its arguments.
PostgreSQL also supports JIT-ing expression execution. And we can find the switch between interpreting and JIT-compiling an expression here.
QuestDB (Ruling: Tree Walker + JIT)
QuestDB wrote about their execution engine recently. When the conditions are right, they'll switch over to a JIT compiler and run native code.
But let's look at the default path. For example, how AND is
implemented. AndBooleanFunction
implements BooleanFunction which implements Function. An
expression can be evaluated by calling a getX() method on the
expression type that implements Function. AndBooleanFunction calls
getBool() on its left and right hand sides. And if we look at the
partial
implementation
of BooleanFunction we'll also see it doing getX() specific
conversions during the call of getX(). So that's a tree-walking
interpreter.
Scylla (Ruling: Tree Walker)
If we take a look at how functions are
evaluated
in Scylla, we see function evaluation first evaluating all of its
arguments. And
the function evaluation function itself returns a
cql3::raw_value. So that's a tree-walking interpreter.
SQLite (Ruling: Virtual Machine)
SQLite's virtual machine is comprehensive and well-documented. It encompasses more than just expression evaluation but the entirety of query execution.
We can find the massive virtual machine switch in src/vdbe.c.
And if we look, for example, at how AND is implemented, we see it
pulling its arguments out of
memory
(already evaluated) and assigning the result back to a designated
point in
memory.
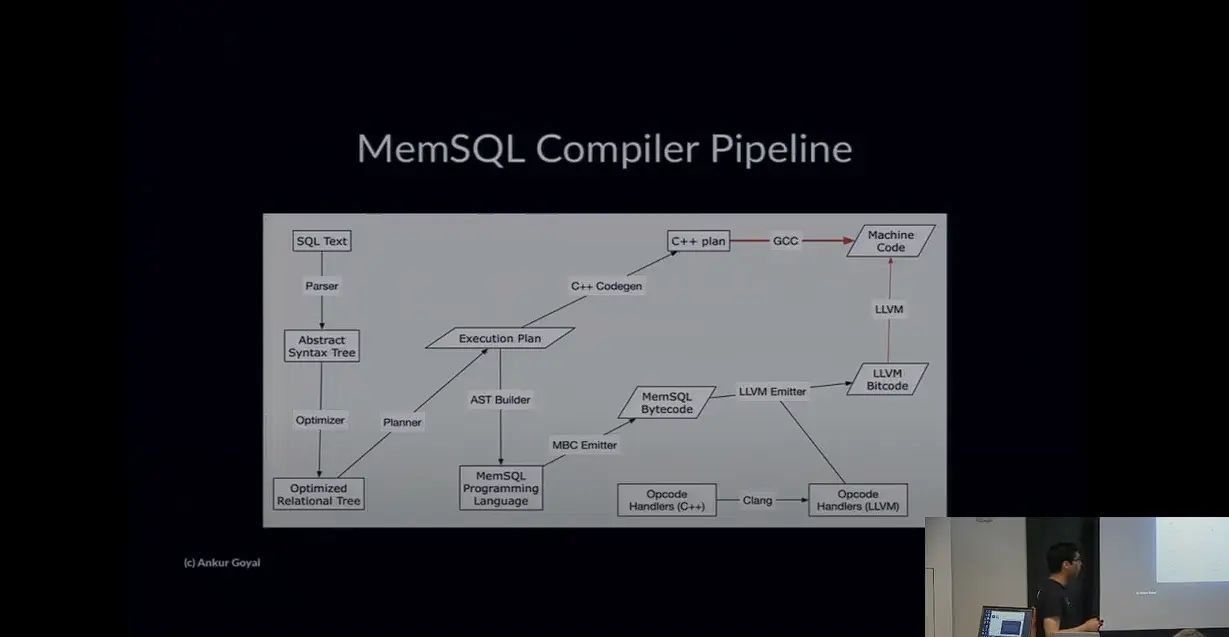
SingleStore (Ruling: Virtual Machine + JIT)
While there's no source code to link to, SingleStore gave a talk at CMU that broke down their query execution pipeline. Their docs also cover the topic.
TiDB (Ruling: Tree Walker)
Similar to DuckDB and ClickHouse, TiDB implements vectorized interpretation. They've written publicly about their switch to this method.
Let's take a look at how if is implemented in TiDB. There is a
vectorized and non-vectorized version of if (in
expression/control_builtin.go
and
expression/control_builtin_generated.go
respectively). So maybe they haven't completely switched over to
vectorized execution or maybe it can only be used in some conditions.
If we look at the non-vectorized version of
if,
we see the condition
evaluated. And
then the then or else is evaluated depending on the result of the
condition. That's
a tree-walking interpreter.
Conclusion
As the DuckDB team points out, vectorized interpretation or JIT compilation seem like the future for database expression execution. These strategies seem particularly important for analytics or time-series workloads. But vectorized interpretation seems to make the most sense for column-wise storage engines. And column-wise storage normally only makes sense for analytics workloads. Still, TiDB and Cockroach are transactional databases that also vectorize execution.
And while SQLite and PostgreSQL use the virtual machine model, it's possible databases with tree-walking interpreters like Scylla and MySQL/MariaDB have decided there is not significant enough gains to be had (for transactional workloads) to justify the complexity of moving to a compiler + virtual machine architecture.
Tree-walking interpreters and virtual machines are also independent from whether or not execution is vectorized. So that will be another interesting dimension to watch: if more databases move toward vectorized execution even if they don't adapt JIT compilation.
Yet another alternative is that maybe as databases mature we'll see compilation tiers similar to what browsers do with JavaScript.
Credits: Thanks Max Bernstein, Alex Miller, and Justin Jaffray for reviewing a draft version of this! And thanks to the #dbs channel on Discord for instigating this post!
I spent some time looking into how various databases execute expressions in their query language.
— Phil Eaton (@eatonphil) September 21, 2023
Most of them have a tree-walking interpreter, some have a virtual machine, and some do just-in-time compilation.
Let's dig into some database code to see!https://t.co/BIGtHKh1X4 pic.twitter.com/nmhe9HmYw7