All code for this post is available on Github.
Let's take a look at how zip files work. Take a small file for example:
$ cat hello.text
Hello!
Let's zip it up.
$ zip test.zip hello.text
adding: hello.text (stored 0%)
$ ls -lah test.zip
-rw-r--r-- 1 phil phil 177 Nov 23 23:04 test.zip
So a 6 byte text file becomes a 177 byte zip file. That is pretty small! Parsing 177 bytes sounds like it can't possibly be too complicated!
Let's hexdump the zip file.
$ hexdump -C test.zip
00000000 50 4b 03 04 0a 00 00 00 00 00 8a b8 77 53 9e d8 |PK..........wS..|
00000010 42 b0 07 00 00 00 07 00 00 00 0a 00 1c 00 68 65 |B.............he|
00000020 6c 6c 6f 2e 74 65 78 74 55 54 09 00 03 74 73 9d |llo.textUT...ts.|
00000030 61 74 73 9d 61 75 78 0b 00 01 04 eb 03 00 00 04 |ats.aux.........|
00000040 eb 03 00 00 48 65 6c 6c 6f 21 0a 50 4b 01 02 1e |....Hello!.PK...|
00000050 03 0a 00 00 00 00 00 8a b8 77 53 9e d8 42 b0 07 |.........wS..B..|
00000060 00 00 00 07 00 00 00 0a 00 18 00 00 00 00 00 01 |................|
00000070 00 00 00 a4 81 00 00 00 00 68 65 6c 6c 6f 2e 74 |.........hello.t|
00000080 65 78 74 55 54 05 00 03 74 73 9d 61 75 78 0b 00 |extUT...ts.aux..|
00000090 01 04 eb 03 00 00 04 eb 03 00 00 50 4b 05 06 00 |...........PK...|
000000a0 00 00 00 01 00 01 00 50 00 00 00 4b 00 00 00 00 |.......P...K....|
000000b0 00 |.|
000000b1
We can see both the file name and the file contents in there.
Structure
Let's take a look at the zip structure defined here. Based on section 4.3.6 it looks like file metadata followed by the file contents are stored one after another with a final chunk of "central directory" metadata.
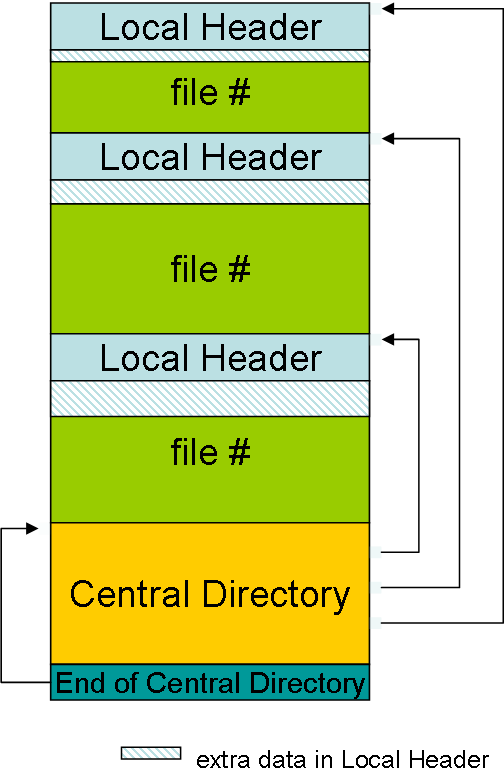
The local header metadata looks like this:
| Field | Size |
|---|---|
| local file header signature | 4 bytes |
| version needed to extract | 2 bytes |
| general purpose bit flag | 2 bytes |
| compression method | 2 bytes |
| last mod file time | 2 bytes |
| last mod file date | 2 bytes |
| crc-32 | 4 bytes |
| compressed size | 4 bytes |
| uncompressed size | 4 bytes |
| file name length | 2 bytes |
| extra field length | 2 bytes |
| file name | variable |
| extra field | variable |
The header signature is a single integer (0x04034b50) in
a valid zip file. We'll ignore version, the general purpose flag, and
the checksum. Compression is either 0 for no compression
or 8 for DEFLATE compression/decompression.
Last modified time and date is MSDOS-style date/time format which is pretty funky.
Let's translate this roughly to Go with some high level flourishes.
package main
import (
"os"
"bytes"
"compress/flate"
"io/ioutil"
"encoding/binary"
"time"
"fmt"
)
type compression uint8
const (
noCompression compression = iota
deflateCompression
)
type localFileHeader struct {
signature uint32
version uint16
bitFlag uint16
compression compression
lastModified time.Time
crc32 uint32
compressedSize uint32
uncompressedSize uint32
fileName string
extraField []byte
fileContents string
}
main
Our entrypoint will read a zip file and keep walking through the file until we stop being able to parse zip file entries.
func main() {
f, err := ioutil.ReadFile(os.Args[1])
if err != nil {
panic(err)
}
end := 0
for end < len(f) {
var err error
var lfh *localFileHeader
var next int
lfh, next, err = parseLocalFileHeader(f, end)
if err == errNotZip && end > 0 {
break
}
if err != nil {
panic(err)
}
end = next
fmt.Println(lfh.lastModified, lfh.fileName, lfh.fileContents)
}
}
Files
For each file we'll fail early if the first four bytes are not the magic zip signature.
var errNotZip = fmt.Errorf("Not a zip file")
func parseLocalFileHeader(bs []byte, start int) (*localFileHeader, int, error) {
signature, i, err := readUint32(bs, start)
if signature != 0x04034b50 {
return nil, 0, errNotZip
}
if err != nil {
return nil, 0, err
}
The basic pattern is that one of these read helpers will take an offset and return a Go value and a new offset. The read helper will do bounds checking. We'll define the read helpers further down.
Let's follow the same pattern to the end of the struct:
version, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
bitFlag, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
compression := noCompression
compressionRaw, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
if compressionRaw == 8 {
compression = deflateCompression
}
lmTime, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
lmDate, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
lastModified := msdosTimeToGoTime(lmDate, lmTime)
crc32, i, err := readUint32(bs, i)
if err != nil {
return nil, 0, err
}
compressedSize, i, err := readUint32(bs, i)
if err != nil {
return nil, 0, err
}
uncompressedSize, i, err := readUint32(bs, i)
if err != nil {
return nil, 0, err
}
fileNameLength, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
extraFieldLength, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
fileName, i, err := readString(bs, i, int(fileNameLength))
if err != nil {
return nil, 0, err
}
extraField, i, err := readBytes(bs, i, int(extraFieldLength))
if err != nil {
return nil, 0, err
}
Now if the file contents are uncompressed we can just copy bytes after the file header. If the file contents are compressed though we'll use Go's builtin DEFLATE support to decompress the bytes after the file header.
var fileContents string
if compression == noCompression {
fileContents, i, err = readString(bs, i, int(uncompressedSize))
if err != nil {
return nil, 0, err
}
} else {
end := i + int(compressedSize)
if end > len(bs) {
return nil, 0, errOverranBuffer
}
flateReader := flate.NewReader(bytes.NewReader(bs[i:end]))
defer flateReader.Close()
read, err := ioutil.ReadAll(flateReader)
if err != nil {
return nil, 0, err
}
fileContents = string(read)
i = end
}
And return the filled out representation:
return &localFileHeader{
signature: signature,
version: version,
bitFlag: bitFlag,
compression: compression,
lastModified: lastModified,
crc32: crc32,
compressedSize: compressedSize,
uncompressedSize: uncompressedSize,
fileName: fileName,
extraField: extraField,
fileContents: fileContents,
}, i, nil
}
Read helpers
Now we just define those read helpers with bounds checking, using Go's builtin libraries for dealing with binary encodings.
var errOverranBuffer = fmt.Errorf("Overran buffer")
func readUint32(bs []byte, offset int) (uint32, int, error) {
end := offset + 4
if end > len(bs) {
return 0, 0, errOverranBuffer
}
return binary.LittleEndian.Uint32(bs[offset:end]), end, nil
}
func readUint16(bs []byte, offset int) (uint16, int, error) {
end := offset+2
if end > len(bs) {
return 0, 0, errOverranBuffer
}
return binary.LittleEndian.Uint16(bs[offset:end]), end, nil
}
And basically only bounds checking for grabbing bytes and strings.
func readBytes(bs []byte, offset int, n int) ([]byte, int, error) {
end := offset + n
if end > len(bs) {
return nil, 0, errOverranBuffer
}
return bs[offset:offset+n], end, nil
}
func readString(bs []byte, offset int, n int) (string, int, error) {
read, end, err := readBytes(bs, offset, n)
return string(read), end, err
}
MSDOS time
At the time zip was created, MSDOS time format was popular, I guess. But it's not popular today so it took a bit of work to finally find an explanation of the format with some code (in C).
func msdosTimeToGoTime(d uint16, t uint16) time.Time {
seconds := int((t & 0x1F) * 2)
minutes := int((t >> 5) & 0x3F)
hours := int(t >> 11)
day := int(d & 0x1F)
month := time.Month((d >> 5) & 0x0F)
year := int((d >> 9) & 0x7F) + 1980
return time.Date(year, month, day, hours, minutes, seconds, 0, time.Local)
}
Tout ensemble
Running it we get:
$ go build
$ ./gozip test.zip
2021-11-23 23:04:20 +0000 UTC hello.text Hello!
That looks good! Now let's try zipping more than one file.
$ cat bye.text
Au revoir!
$ rm test.zip
$ zip test.zip *.text
adding: bye.text (stored 0%)
adding: hello.text (stored 0%)
$ ./gozip test.zip
2021-11-24 03:40:00 +0000 UTC bye.text Au revoir!
2021-11-23 23:04:20 +0000 UTC hello.text Hello!
Fab.
Notes
There are many parts of the standard to deal with (e.g. directories) and many common extensions. I'm ignoring them.
There's some space left at the end of the file which is probably the "central directory" metadata but I haven't dug into that. Understanding those last remaining bits are probably necessary if I want to be able to create zip archives.
I wrote a new post on building a zip archive reader in Go!https://t.co/U0Yg2powlP pic.twitter.com/ns5dF3mjIx
— Phil Eaton (@phil_eaton) November 24, 2021